
Hello Toasters,
We had an incident where a FAS6040 running 8.0.1 gave very slow response to a variety of requests. This resulted in a bunch of Linux VMs experiencing failed disk I/O requests, which resulted in corrupted local Linux filesystems. One Linux VM logged that it waited 180 sec. for a disk I/O to complete.
The filer did not reboot, and recovered on its own, but we are very interested in figuring out what happened and if we can avoid it (known bug?, should we upgrade ONTAP?)
This 6040 does a variety of jobs -- NFS server for a Communigate Pro email system, NFS volumes for VMWARE, and it even has a few FC SAN LUNs used by sharepoint. In general it does not appear to be overloaded. It's been up for over 300 days with no problems. The CF partner filer experienced no problems at that time and it also holds VMWARE volumes and mail volumes.
At the time of the outage the /etc/messages file indicated a slow NFS response (93 sec) to one of the Communigate servers. It also indicated that a FC LUN was reset by the sharepoint server. I'm guessing due to delayed response. The mail and sharepoint volumes are in the same aggregate. I see three resets for the LUN in /etc/messages.
I looked in /etc/log/ems at about the time of the outage (Tue May 22 17:30 EDT) I see that a raid scrub of a raid group in the mail/sharepoint aggregate completed with no errors. I also see wafl_cp_toolong_warning_1 and wafl_cp_slovol_warning_1 for a different aggregate (which contains VMs). I see several of these, which I presume are caused by slow completion of CPs.
I don't know if these caused the problem or were caused by the problem.
Anyone have any suggestions for further investigation or diagnosis? Any other logs to look at? Everything is fine now and has been running fine since the outage.
Thanks,
Steve Losen scl@virginia.edu phone: 434-924-0640
University of Virginia ITC Unix Support

Le 24/05/2012 08:28, Steve Losen a �crit:
Hello Toasters,
We had an incident where a FAS6040 running 8.0.1 gave very slow response to a variety of requests. This resulted in a bunch of Linux VMs experiencing failed disk I/O requests, which resulted in corrupted local Linux filesystems. One Linux VM logged that it waited 180 sec. for a disk I/O to complete.
The filer did not reboot, and recovered on its own, but we are very interested in figuring out what happened and if we can avoid it (known bug?, should we upgrade ONTAP?)
This 6040 does a variety of jobs -- NFS server for a Communigate Pro email system, NFS volumes for VMWARE, and it even has a few FC SAN LUNs used by sharepoint. In general it does not appear to be overloaded. It's been up for over 300 days with no problems. The CF partner filer experienced no problems at that time and it also holds VMWARE volumes and mail volumes.
At the time of the outage the /etc/messages file indicated a slow NFS response (93 sec) to one of the Communigate servers. It also indicated that a FC LUN was reset by the sharepoint server. I'm guessing due to delayed response. The mail and sharepoint volumes are in the same aggregate. I see three resets for the LUN in /etc/messages.
I looked in /etc/log/ems at about the time of the outage (Tue May 22 17:30 EDT) I see that a raid scrub of a raid group in the mail/sharepoint aggregate completed with no errors. I also see wafl_cp_toolong_warning_1 and wafl_cp_slovol_warning_1 for a different aggregate (which contains VMs). I see several of these, which I presume are caused by slow completion of CPs.
I don't know if these caused the problem or were caused by the problem.
Anyone have any suggestions for further investigation or diagnosis? Any other logs to look at? Everything is fine now and has been running fine since the outage.
I would start by looking at the graphs of the netapp interfaces traffic, cpu and iops to see if a storage client suddenly caused an activity spike which slowed down everything else.

we had some slow down a while back due to dedupe processes running at the deault midnight. Not 93 seconds worth, but noticeable slowness. WE stagger them now obviously and don't run dedupe on our vm vols everynight Some questions would be:how many disks/type/speed are in the aggr? If the disks for the VM's are not aligned, that's a big oneMaybe need to add more disks or run a reallocate against the vols. In my case, I have to run reallocate on my vols. I have hot disks. A while back, I had an issue with the filer running out of memory and I was dropping packets (very nerve-racking). That was 7.x days.
Date: Thu, 24 May 2012 14:50:09 +0200 From: amon@aelita.org To: scl@virginia.edu Subject: Re: Diagnosing outage on FAS6040 running 8.0.1 7-mode CC: toasters@teaparty.net
Le 24/05/2012 08:28, Steve Losen a écrit:
Hello Toasters,
We had an incident where a FAS6040 running 8.0.1 gave very slow response to a variety of requests. This resulted in a bunch of Linux VMs experiencing failed disk I/O requests, which resulted in corrupted local Linux filesystems. One Linux VM logged that it waited 180 sec. for a disk I/O to complete.
The filer did not reboot, and recovered on its own, but we are very interested in figuring out what happened and if we can avoid it (known bug?, should we upgrade ONTAP?)
This 6040 does a variety of jobs -- NFS server for a Communigate Pro email system, NFS volumes for VMWARE, and it even has a few FC SAN LUNs used by sharepoint. In general it does not appear to be overloaded. It's been up for over 300 days with no problems. The CF partner filer experienced no problems at that time and it also holds VMWARE volumes and mail volumes.
At the time of the outage the /etc/messages file indicated a slow NFS response (93 sec) to one of the Communigate servers. It also indicated that a FC LUN was reset by the sharepoint server. I'm guessing due to delayed response. The mail and sharepoint volumes are in the same aggregate. I see three resets for the LUN in /etc/messages.
I looked in /etc/log/ems at about the time of the outage (Tue May 22 17:30 EDT) I see that a raid scrub of a raid group in the mail/sharepoint aggregate completed with no errors. I also see wafl_cp_toolong_warning_1 and wafl_cp_slovol_warning_1 for a different aggregate (which contains VMs). I see several of these, which I presume are caused by slow completion of CPs.
I don't know if these caused the problem or were caused by the problem.
Anyone have any suggestions for further investigation or diagnosis? Any other logs to look at? Everything is fine now and has been running fine since the outage.
I would start by looking at the graphs of the netapp interfaces traffic, cpu and iops to see if a storage client suddenly caused an activity spike which slowed down everything else.

Hi Steve,
1) Use netapp support - ask specifically if there are any relevant known bugs in your 8.0.1 version - ask for a reply by a certain time 2) Use performance advisor to help deconstruct where the finite number of IOPs are going: http://www.vmadmin.info/2010/07/vmware-and-netapp-deconstructing.html 2a) Do the disk busy view spikes strongly correlate to the latency view spikes ?
2b) Use PA to see your base line "normal" IOPS per aggr, also use the latency per IOPS chart to calculate your AGGRs IOPS capacity @ 20ms latency (VMs don't like much more than 20ms at peak) 3) Check unaligned IO is contributing to the latency spike by tracking partial writes: http://www.vmadmin.info/2010/07/quantifying-vmdk-misalignment.html
On May 24, 2012, at 5:28 AM, Steve Losen wrote:
Hello Toasters,
We had an incident where a FAS6040 running 8.0.1 gave very slow response to a variety of requests. This resulted in a bunch of Linux VMs experiencing failed disk I/O requests, which resulted in corrupted local Linux filesystems. One Linux VM logged that it waited 180 sec. for a disk I/O to complete.
The filer did not reboot, and recovered on its own, but we are very interested in figuring out what happened and if we can avoid it (known bug?, should we upgrade ONTAP?)
This 6040 does a variety of jobs -- NFS server for a Communigate Pro email system, NFS volumes for VMWARE, and it even has a few FC SAN LUNs used by sharepoint. In general it does not appear to be overloaded. It's been up for over 300 days with no problems. The CF partner filer experienced no problems at that time and it also holds VMWARE volumes and mail volumes.
At the time of the outage the /etc/messages file indicated a slow NFS response (93 sec) to one of the Communigate servers. It also indicated that a FC LUN was reset by the sharepoint server. I'm guessing due to delayed response. The mail and sharepoint volumes are in the same aggregate. I see three resets for the LUN in /etc/messages.
I looked in /etc/log/ems at about the time of the outage (Tue May 22 17:30 EDT) I see that a raid scrub of a raid group in the mail/sharepoint aggregate completed with no errors. I also see wafl_cp_toolong_warning_1 and wafl_cp_slovol_warning_1 for a different aggregate (which contains VMs). I see several of these, which I presume are caused by slow completion of CPs.
I don't know if these caused the problem or were caused by the problem.
Anyone have any suggestions for further investigation or diagnosis? Any other logs to look at? Everything is fine now and has been running fine since the outage.
Thanks,
Steve Losen scl@virginia.edu phone: 434-924-0640
University of Virginia ITC Unix Support
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
{kind=link}

Hi Steve,
If you have a valid support contract with NetApp I highly recommend you open a support case. Note, they probably won't do much without a perfstat taken when you're experiencing the problem. Therefore I suggest pre-empting this by downloading the perfstat tool at http://support.netapp.com/NOW/download/tools/perfstat/ and have it ready in case the problem reappears.
There are a number of things that could be causing this. I would take a stab that the Kahuna processor is running through the roof, causing disk latency to be well in excess of the 20ms (you never what to reach). Some possible causes are:
. Not enough spindles to serve the IO demand on the FAS.
. Block misalignment, effectively doubling your IO usage.
. CPU running too hot - can be caused by SnapMirror jobs, Dedupe, deswizzling, etc
. Large CIFS directories have been known to cause this, although I don't think you're running CIFS.
All in all if your system is sized correctly, and you don't have bock misalignment, you *shouldn't* have problems with your system. The FAS6040 is a powerful box, something as simple as adding more spindles or introducing FlashCache should reduce this problem from reoccurring. Alternatively try moving some of the load to the partner controller, assuming that controller is under less load.
I'd also suggest you check out the mbralign tool at http://support.netapp.com/NOW/download/tools/mbralign/ to check alignment issues in your VMware environment.
-Jonathon
From: toasters-bounces@teaparty.net [mailto:toasters-bounces@teaparty.net] On Behalf Of Fletcher Cocquyt Sent: Thursday, 24 May 2012 11:57 PM To: Steve Losen Cc: toasters@teaparty.net Subject: Re: Diagnosing outage on FAS6040 running 8.0.1 7-mode
Hi Steve,
1) Use netapp support - ask specifically if there are any relevant known bugs in your 8.0.1 version - ask for a reply by a certain time
2) Use performance advisor to help deconstruct where the finite number of IOPs are going: http://www.vmadmin.info/2010/07/vmware-and-netapp-deconstructing.html
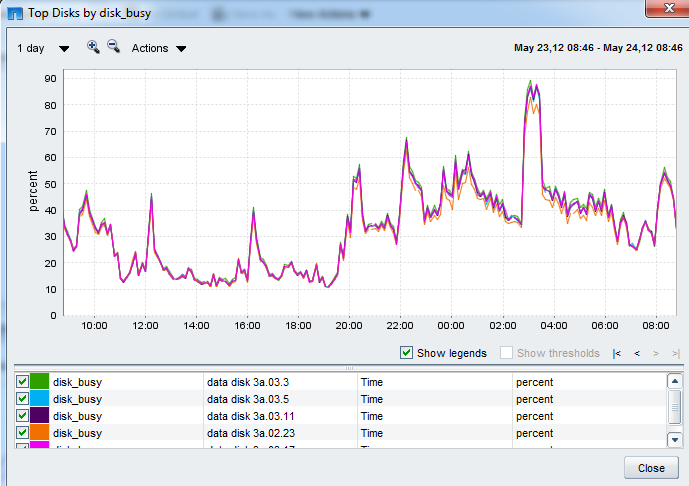
2a) Do the disk busy view spikes strongly correlate to the latency view spikes ?
2b) Use PA to see your base line "normal" IOPS per aggr, also use the latency per IOPS chart to calculate your AGGRs IOPS capacity @ 20ms latency (VMs don't like much more than 20ms at peak)
3) Check unaligned IO is contributing to the latency spike by tracking partial writes: http://www.vmadmin.info/2010/07/quantifying-vmdk-misalignment.html
On May 24, 2012, at 5:28 AM, Steve Losen wrote:
Hello Toasters,
We had an incident where a FAS6040 running 8.0.1 gave very slow response to a variety of requests. This resulted in a bunch of Linux VMs experiencing failed disk I/O requests, which resulted in corrupted local Linux filesystems. One Linux VM logged that it waited 180 sec. for a disk I/O to complete.
The filer did not reboot, and recovered on its own, but we are very interested in figuring out what happened and if we can avoid it (known bug?, should we upgrade ONTAP?)
This 6040 does a variety of jobs -- NFS server for a Communigate Pro email system, NFS volumes for VMWARE, and it even has a few FC SAN LUNs used by sharepoint. In general it does not appear to be overloaded. It's been up for over 300 days with no problems. The CF partner filer experienced no problems at that time and it also holds VMWARE volumes and mail volumes.
At the time of the outage the /etc/messages file indicated a slow NFS response (93 sec) to one of the Communigate servers. It also indicated that a FC LUN was reset by the sharepoint server. I'm guessing due to delayed response. The mail and sharepoint volumes are in the same aggregate. I see three resets for the LUN in /etc/messages.
I looked in /etc/log/ems at about the time of the outage (Tue May 22 17:30 EDT) I see that a raid scrub of a raid group in the mail/sharepoint aggregate completed with no errors. I also see wafl_cp_toolong_warning_1 and wafl_cp_slovol_warning_1 for a different aggregate (which contains VMs). I see several of these, which I presume are caused by slow completion of CPs.
I don't know if these caused the problem or were caused by the problem.
Anyone have any suggestions for further investigation or diagnosis? Any other logs to look at? Everything is fine now and has been running fine since the outage.
Thanks,
Steve Losen scl@virginia.edu phone: 434-924-0640
University of Virginia ITC Unix Support
_______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
{kind=link}
Hi Folks,
Thanks so much for all of your suggestions regarding our 6040 outage. As always, very helpful.
While this may not explain the outage, we have noticed some I/O load spikes coming from our email servers since the outage. We have tracked it down to very inefficient processing of mailboxes. Apparently one mail client (Outlook) is deleting multiple messages from a mail folder with a sequence of individual message delete commands. Instead it could use a single command with a list of messages to delete. The mail server is Communigate (not Exchange). The mail folders are flat files so whenever messages are deleted, the tail end of the folder gets rewritten, minus the deleted messages.
Yesterday a single 1.5 GB folder was being read from the filer and written back to the filer again and again to delete numerous messages near the front, one at a time. The user confirmed that she had marked a bunch of messages for delete and then committed the change. We got some complaints about slow email performance from folks who were connected to that particular email server (we have a cluster). But everything else was OK, and the filer handled it gracefully.
It would be nice if Communigate would logically delete messages and rewrite folders in a background process after some number of logical deletes have accumulated. Maybe that is a config option...
Steve Losen scl@virginia.edu phone: 434-924-0640
University of Virginia ITC Unix Support
-
 Fletcher Cocquyt
Fletcher Cocquyt -
 Herve Boulouis
Herve Boulouis -
 Jonathon Lanzon
Jonathon Lanzon -
 steve klise
steve klise -
 Steve Losen
Steve Losen