
3270 cluster, OnTAP 8.1-7mode
We are investigating a SATA aggregate showing repeated 5am disk 100% busy spikes without its volumes showing any corresponding IOPS spike as reported by Netapp Management Console (NMC). The 5am disk busy spikes correlate with very high latency on volumes on a different SAS aggregate. These volumes host VMs which then timeout, some needing reboots. Today when I heard from Netapp support after reviewing my perfstat the engineer reported this is expected since NVRAM buffers are shared btw aggregates.
But when I dig further into the NMC stats I see the SATA aggregate disk busy actually corresponds to a DROP in IOPS on the 3 volumes hosted on the SATA aggregate - almost like some internal aggregate operations are starving out the external volume ops. I checked the snapshots (vol and aggr), snap mirror, dedup and none of the usual suspects were running.
When I look at the NMC throughput graphs and switch on the legend - it shows a 5am READ blocks/sec spike corresponding perfectly to the disk busy.
Where are these AGGR level READ operations coming from that are missing from the constituent volume IOPS, and in fact seem to be starving out volume level IO?
I don't see much in the messages log, but will check the rest of the logs for internal type OPS
thanks for any insight

That is normal..
I do see those...
Just make sure, that network data - are not heavily IN at that time
From: toasters-bounces@teaparty.net [mailto:toasters-bounces@teaparty.net] On Behalf Of Fletcher Cocquyt Sent: Thursday, January 24, 2013 12:28 AM To: toasters@teaparty.net Lists Subject: Aggregate Disk Busy 100% with volume IOPS low
3270 cluster, OnTAP 8.1-7mode
We are investigating a SATA aggregate showing repeated 5am disk 100% busy spikes without its volumes showing any corresponding IOPS spike as reported by Netapp Management Console (NMC).
The 5am disk busy spikes correlate with very high latency on volumes on a different SAS aggregate. These volumes host VMs which then timeout, some needing reboots.
Today when I heard from Netapp support after reviewing my perfstat the engineer reported this is expected since NVRAM buffers are shared btw aggregates.
But when I dig further into the NMC stats I see the SATA aggregate disk busy actually corresponds to a DROP in IOPS on the 3 volumes hosted on the SATA aggregate - almost like some internal aggregate operations are starving out the external volume ops.
I checked the snapshots (vol and aggr), snap mirror, dedup and none of the usual suspects were running.
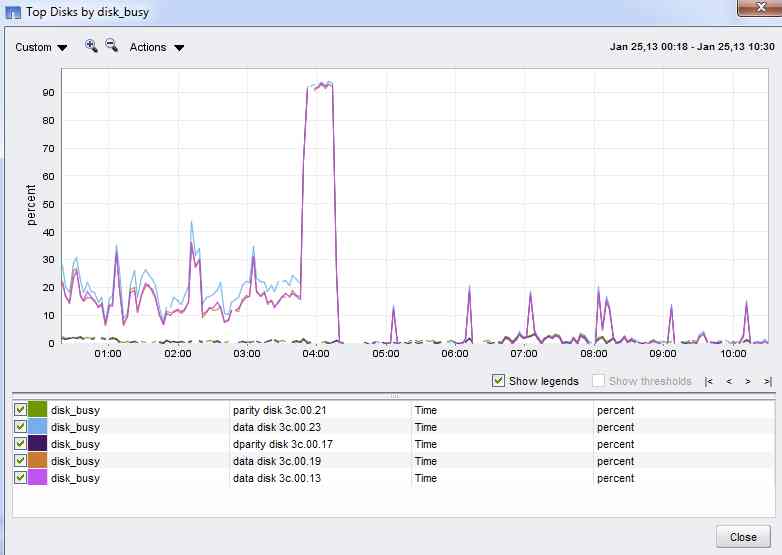
When I look at the NMC throughput graphs and switch on the legend - it shows a 5am READ blocks/sec spike corresponding perfectly to the disk busy.
Where are these AGGR level READ operations coming from that are missing from the constituent volume IOPS, and in fact seem to be starving out volume level IO?
I don't see much in the messages log, but will check the rest of the logs for internal type OPS
thanks for any insight
We are still seeing physical disk IO (95% reads) spikes without any volume level IO. I'm trying to determine if its related to large file deletions or something else - I might have to go digging in the perfstats myself. Are there any tools available to us to pick apart and analyze perfstats?
thanks
On Jan 24, 2013, at 4:24 AM, "Uddhav Regmi" uregmi111@gmail.com wrote:
That is normal…. I do see those…..
Just make sure, that network data – are not heavily IN at that time
From: toasters-bounces@teaparty.net [mailto:toasters-bounces@teaparty.net] On Behalf Of Fletcher Cocquyt Sent: Thursday, January 24, 2013 12:28 AM To: toasters@teaparty.net Lists Subject: Aggregate Disk Busy 100% with volume IOPS low
3270 cluster, OnTAP 8.1-7mode
We are investigating a SATA aggregate showing repeated 5am disk 100% busy spikes without its volumes showing any corresponding IOPS spike as reported by Netapp Management Console (NMC). The 5am disk busy spikes correlate with very high latency on volumes on a different SAS aggregate. These volumes host VMs which then timeout, some needing reboots. Today when I heard from Netapp support after reviewing my perfstat the engineer reported this is expected since NVRAM buffers are shared btw aggregates.
But when I dig further into the NMC stats I see the SATA aggregate disk busy actually corresponds to a DROP in IOPS on the 3 volumes hosted on the SATA aggregate - almost like some internal aggregate operations are starving out the external volume ops. I checked the snapshots (vol and aggr), snap mirror, dedup and none of the usual suspects were running.
When I look at the NMC throughput graphs and switch on the legend - it shows a 5am READ blocks/sec spike corresponding perfectly to the disk busy.
Where are these AGGR level READ operations coming from that are missing from the constituent volume IOPS, and in fact seem to be starving out volume level IO?
I don't see much in the messages log, but will check the rest of the logs for internal type OPS
thanks for any insight
{kind=link}

Fletcher,
It sounds like you already have a case open with NetApp support. If they are saying this is normal behavior, you may also want to reach out to your NetApp partner and sales rep to order some professional services for a performance engineer to analyze this.
We would be willing to take a quick look at this if you upload your perfstats somewhere (like ADrive or another cloud storage site) and share them with us. We also have an FTP server you can upload if needed.
Thank you, Tim
From: toasters-bounces@teaparty.net [mailto:toasters-bounces@teaparty.net] On Behalf Of Fletcher Cocquyt Sent: Friday, January 25, 2013 4:48 PM To: Uddhav Regmi Cc: toasters@teaparty.net Subject: Re: Aggregate Disk Busy 100% with volume IOPS low
We are still seeing physical disk IO (95% reads) spikes without any volume level IO.
I'm trying to determine if its related to large file deletions or something else - I might have to go digging in the perfstats myself.
Are there any tools available to us to pick apart and analyze perfstats?
thanks
On Jan 24, 2013, at 4:24 AM, "Uddhav Regmi" uregmi111@gmail.com wrote:
That is normal....
I do see those.....
Just make sure, that network data - are not heavily IN at that time
From: toasters-bounces@teaparty.net mailto:toasters-bounces@teaparty.net [mailto:toasters- bounces@teaparty.net mailto:bounces@teaparty.net ] On Behalf Of Fletcher Cocquyt Sent: Thursday, January 24, 2013 12:28 AM To: toasters@teaparty.net mailto:toasters@teaparty.net Lists Subject: Aggregate Disk Busy 100% with volume IOPS low
3270 cluster, OnTAP 8.1-7mode
We are investigating a SATA aggregate showing repeated 5am disk 100% busy spikes without its volumes showing any corresponding IOPS spike as reported by Netapp Management Console (NMC).
The 5am disk busy spikes correlate with very high latency on volumes on a different SAS aggregate. These volumes host VMs which then timeout, some needing reboots.
Today when I heard from Netapp support after reviewing my perfstat the engineer reported this is expected since NVRAM buffers are shared btw aggregates.
But when I dig further into the NMC stats I see the SATA aggregate disk busy actually corresponds to a DROP in IOPS on the 3 volumes hosted on the SATA aggregate - almost like some internal aggregate operations are starving out the external volume ops.
I checked the snapshots (vol and aggr), snap mirror, dedup and none of the usual suspects were running.
When I look at the NMC throughput graphs and switch on the legend - it shows a 5am READ blocks/sec spike corresponding perfectly to the disk busy.
Where are these AGGR level READ operations coming from that are missing from the constituent volume IOPS, and in fact seem to be starving out volume level IO?
I don't see much in the messages log, but will check the rest of the logs for internal type OPS
thanks for any insight
{kind=link}

Try doing a 'ps -c 1' or a wafltop show (double check the syntax) while you're getting the spike; those will probably help you narrow down the processes that are using your disks. Both are priv set advanced/diag commands.
Nick
-- Sent from my mobile device
On Jan 25, 2013, at 4:47 PM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
We are still seeing physical disk IO (95% reads) spikes without any volume level IO. I'm trying to determine if its related to large file deletions or something else - I might have to go digging in the perfstats myself. Are there any tools available to us to pick apart and analyze perfstats?
<sataspike.jpg>
thanks
On Jan 24, 2013, at 4:24 AM, "Uddhav Regmi" uregmi111@gmail.com wrote:
That is normal…. I do see those…..
Just make sure, that network data – are not heavily IN at that time
From: toasters-bounces@teaparty.net [mailto:toasters-bounces@teaparty.net] On Behalf Of Fletcher Cocquyt Sent: Thursday, January 24, 2013 12:28 AM To: toasters@teaparty.net Lists Subject: Aggregate Disk Busy 100% with volume IOPS low
3270 cluster, OnTAP 8.1-7mode
We are investigating a SATA aggregate showing repeated 5am disk 100% busy spikes without its volumes showing any corresponding IOPS spike as reported by Netapp Management Console (NMC). The 5am disk busy spikes correlate with very high latency on volumes on a different SAS aggregate. These volumes host VMs which then timeout, some needing reboots. Today when I heard from Netapp support after reviewing my perfstat the engineer reported this is expected since NVRAM buffers are shared btw aggregates.
But when I dig further into the NMC stats I see the SATA aggregate disk busy actually corresponds to a DROP in IOPS on the 3 volumes hosted on the SATA aggregate - almost like some internal aggregate operations are starving out the external volume ops. I checked the snapshots (vol and aggr), snap mirror, dedup and none of the usual suspects were running.
When I look at the NMC throughput graphs and switch on the legend - it shows a 5am READ blocks/sec spike corresponding perfectly to the disk busy.
Where are these AGGR level READ operations coming from that are missing from the constituent volume IOPS, and in fact seem to be starving out volume level IO?
I don't see much in the messages log, but will check the rest of the logs for internal type OPS
thanks for any insight
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
Do you have a mixed aggregate in this box ? How large ? 64 and 32 both ? How large each one ? or 64 only – how large ?
Which shelf you have and what are disk IOPs you have, send me info privately……
From: Nicholas Bernstein [mailto:nick@nicholasbernstein.com] Sent: Friday, January 25, 2013 8:33 PM To: Fletcher Cocquyt Cc: Uddhav Regmi; toasters@teaparty.net Subject: Re: Aggregate Disk Busy 100% with volume IOPS low
Try doing a 'ps -c 1' or a wafltop show (double check the syntax) while you're getting the spike; those will probably help you narrow down the processes that are using your disks. Both are priv set advanced/diag commands.
Nick
--
Sent from my mobile device
On Jan 25, 2013, at 4:47 PM, Fletcher Cocquyt <fcocquyt@stanford.edu mailto:fcocquyt@stanford.edu > wrote:
We are still seeing physical disk IO (95% reads) spikes without any volume level IO.
I'm trying to determine if its related to large file deletions or something else - I might have to go digging in the perfstats myself.
Are there any tools available to us to pick apart and analyze perfstats?
<sataspike.jpg>
thanks
On Jan 24, 2013, at 4:24 AM, "Uddhav Regmi" <uregmi111@gmail.com mailto:uregmi111@gmail.com > wrote:
That is normal….
I do see those…..
Just make sure, that network data – are not heavily IN at that time
From: mailto:toasters-bounces@teaparty.net toasters-bounces@teaparty.net [mailto:toasters- mailto:bounces@teaparty.net bounces@teaparty.net] On Behalf Of Fletcher Cocquyt Sent: Thursday, January 24, 2013 12:28 AM To: mailto:toasters@teaparty.net toasters@teaparty.net Lists Subject: Aggregate Disk Busy 100% with volume IOPS low
3270 cluster, OnTAP 8.1-7mode
We are investigating a SATA aggregate showing repeated 5am disk 100% busy spikes without its volumes showing any corresponding IOPS spike as reported by Netapp Management Console (NMC).
The 5am disk busy spikes correlate with very high latency on volumes on a different SAS aggregate. These volumes host VMs which then timeout, some needing reboots.
Today when I heard from Netapp support after reviewing my perfstat the engineer reported this is expected since NVRAM buffers are shared btw aggregates.
But when I dig further into the NMC stats I see the SATA aggregate disk busy actually corresponds to a DROP in IOPS on the 3 volumes hosted on the SATA aggregate - almost like some internal aggregate operations are starving out the external volume ops.
I checked the snapshots (vol and aggr), snap mirror, dedup and none of the usual suspects were running.
When I look at the NMC throughput graphs and switch on the legend - it shows a 5am READ blocks/sec spike corresponding perfectly to the disk busy.
Where are these AGGR level READ operations coming from that are missing from the constituent volume IOPS, and in fact seem to be starving out volume level IO?
I don't see much in the messages log, but will check the rest of the logs for internal type OPS
thanks for any insight
_______________________________________________ Toasters mailing list Toasters@teaparty.net mailto:Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
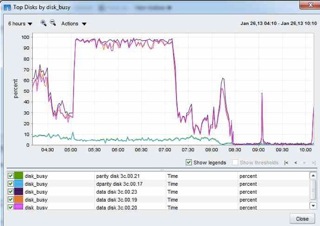
On Nick's advice I setup a job to log both wafltop and ps -c 1 once per minute - and we had a sustained sata0 disk busy from 5am-7am as reported by NMC. First question I have from wafltop show is - what is the first row (sata0::file i/o) reporting ? What could be the source of these 28907 non-volume specific Read IOs?
Application MB Total MB Read(STD) MB Write(STD) Read IOs(STD) Write IOs(STD) ----------- -------- ------------ ------------- ------------- -------------- sata0::file i/o: 5860 5830 30 28907 0 sata0:backup:nfsv3: 608 0 608 31 0
I'm just starting to go through the data
aggr status Aggr State Status Options sata0 online raid_dp, aggr nosnap=on, raidsize=12 64-bit aggr2 online raid_dp, aggr nosnap=on, raidsize=19 64-bit aggr1 online raid_dp, aggr root, nosnap=on, raidsize=14 32-bit na04*> df -Ah Aggregate total used avail capacity aggr1 13TB 11TB 1431GB 89% aggr2 19TB 14TB 5305GB 74% sata0 27TB 19TB 8027GB 72%
thanks
On Jan 25, 2013, at 5:33 PM, Nicholas Bernstein nick@nicholasbernstein.com wrote:
Try doing a 'ps -c 1' or a wafltop show (double check the syntax) while you're getting the spike; those will probably help you narrow down the processes that are using your disks. Both are priv set advanced/diag commands.
Nick
{kind=link}
Usually the ps will show you the process that's using the io indirectly, since its also probably using some CPU. Disk scrub, media scrub, reallocate_measure are just a couple things I can think off off the top of my head that are things that could cause read io.
Stats explain should be able to give you more info on that counter. Sorry this don't a more useful response, I'm on my phone and sick in bed. :/
-- Sent from my mobile device
On Jan 26, 2013, at 10:15 AM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
On Nick's advice I setup a job to log both wafltop and ps -c 1 once per minute - and we had a sustained sata0 disk busy from 5am-7am as reported by NMC. First question I have from wafltop show is - what is the first row (sata0::file i/o) reporting ? What could be the source of these 28907 non-volume specific Read IOs?
Application MB Total MB Read(STD) MB Write(STD) Read IOs(STD) Write IOs(STD) ----------- -------- ------------ ------------- ------------- -------------- sata0::file i/o: 5860 5830 30 28907 0sata0:backup:nfsv3: 608 0 608 31 0
I'm just starting to go through the data
aggr status Aggr State Status Options sata0 online raid_dp, aggr nosnap=on, raidsize=12 64-bit aggr2 online raid_dp, aggr nosnap=on, raidsize=19 64-bit aggr1 online raid_dp, aggr root, nosnap=on, raidsize=14 32-bit na04*> df -Ah Aggregate total used avail capacity aggr1 13TB 11TB 1431GB 89% aggr2 19TB 14TB 5305GB 74% sata0 27TB 19TB 8027GB 72%
<sataIOPSJan26.jpeg>
thanks
On Jan 25, 2013, at 5:33 PM, Nicholas Bernstein nick@nicholasbernstein.com wrote:
Try doing a 'ps -c 1' or a wafltop show (double check the syntax) while you're getting the spike; those will probably help you narrow down the processes that are using your disks. Both are priv set advanced/diag commands.
Nick
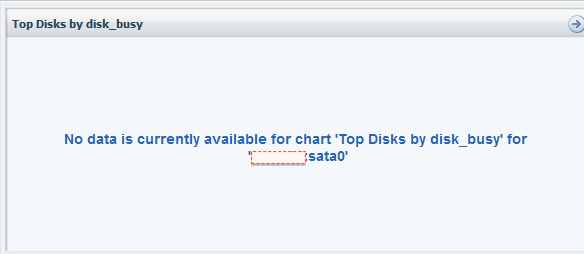
Anyone know why NMC 3.1 (DFM 5.1.0) sometimes reports "No data is currently available…"? and how to fix? Makes it even harder to track issues when the reporting tools fail. thanks
On Jan 26, 2013, at 5:42 PM, Nicholas Bernstein nick@nicholasbernstein.com wrote:
Usually the ps will show you the process that's using the io indirectly, since its also probably using some CPU. Disk scrub, media scrub, reallocate_measure are just a couple things I can think off off the top of my head that are things that could cause read io.
Stats explain should be able to give you more info on that counter. Sorry this don't a more useful response, I'm on my phone and sick in bed. :/
-- Sent from my mobile device
On Jan 26, 2013, at 10:15 AM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
On Nick's advice I setup a job to log both wafltop and ps -c 1 once per minute - and we had a sustained sata0 disk busy from 5am-7am as reported by NMC. First question I have from wafltop show is - what is the first row (sata0::file i/o) reporting ? What could be the source of these 28907 non-volume specific Read IOs?
Application MB Total MB Read(STD) MB Write(STD) Read IOs(STD) Write IOs(STD) ----------- -------- ------------ ------------- ------------- -------------- sata0::file i/o: 5860 5830 30 28907 0sata0:backup:nfsv3: 608 0 608 31 0
I'm just starting to go through the data
aggr status Aggr State Status Options sata0 online raid_dp, aggr nosnap=on, raidsize=12 64-bit aggr2 online raid_dp, aggr nosnap=on, raidsize=19 64-bit aggr1 online raid_dp, aggr root, nosnap=on, raidsize=14 32-bit na04*> df -Ah Aggregate total used avail capacity aggr1 13TB 11TB 1431GB 89% aggr2 19TB 14TB 5305GB 74% sata0 27TB 19TB 8027GB 72%
<sataIOPSJan26.jpeg>
thanks
On Jan 25, 2013, at 5:33 PM, Nicholas Bernstein nick@nicholasbernstein.com wrote:
Try doing a 'ps -c 1' or a wafltop show (double check the syntax) while you're getting the spike; those will probably help you narrow down the processes that are using your disks. Both are priv set advanced/diag commands.
Nick
{kind=link}

Shouldn't you be using version 3.2 with DFM 5.1?
On Jan 28, 2013, at 11:18 AM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
Anyone know why NMC 3.1 (DFM 5.1.0) sometimes reports "No data is currently available…"? and how to fix? Makes it even harder to track issues when the reporting tools fail. thanks
<nodatasata0.jpg>
On Jan 26, 2013, at 5:42 PM, Nicholas Bernstein nick@nicholasbernstein.com wrote:
Usually the ps will show you the process that's using the io indirectly, since its also probably using some CPU. Disk scrub, media scrub, reallocate_measure are just a couple things I can think off off the top of my head that are things that could cause read io.
Stats explain should be able to give you more info on that counter. Sorry this don't a more useful response, I'm on my phone and sick in bed. :/
-- Sent from my mobile device
On Jan 26, 2013, at 10:15 AM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
On Nick's advice I setup a job to log both wafltop and ps -c 1 once per minute - and we had a sustained sata0 disk busy from 5am-7am as reported by NMC. First question I have from wafltop show is - what is the first row (sata0::file i/o) reporting ? What could be the source of these 28907 non-volume specific Read IOs?
Application MB Total MB Read(STD) MB Write(STD) Read IOs(STD) Write IOs(STD) ----------- -------- ------------ ------------- ------------- -------------- sata0::file i/o: 5860 5830 30 28907 0sata0:backup:nfsv3: 608 0 608 31 0
I'm just starting to go through the data
aggr status Aggr State Status Options sata0 online raid_dp, aggr nosnap=on, raidsize=12 64-bit aggr2 online raid_dp, aggr nosnap=on, raidsize=19 64-bit aggr1 online raid_dp, aggr root, nosnap=on, raidsize=14 32-bit na04*> df -Ah Aggregate total used avail capacity aggr1 13TB 11TB 1431GB 89% aggr2 19TB 14TB 5305GB 74% sata0 27TB 19TB 8027GB 72%
<sataIOPSJan26.jpeg>
thanks
On Jan 25, 2013, at 5:33 PM, Nicholas Bernstein nick@nicholasbernstein.com wrote:
Try doing a 'ps -c 1' or a wafltop show (double check the syntax) while you're getting the spike; those will probably help you narrow down the processes that are using your disks. Both are priv set advanced/diag commands.
Nick
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
Thanks Scott - upgraded to 3.2 - no issues - this list is such a great resource
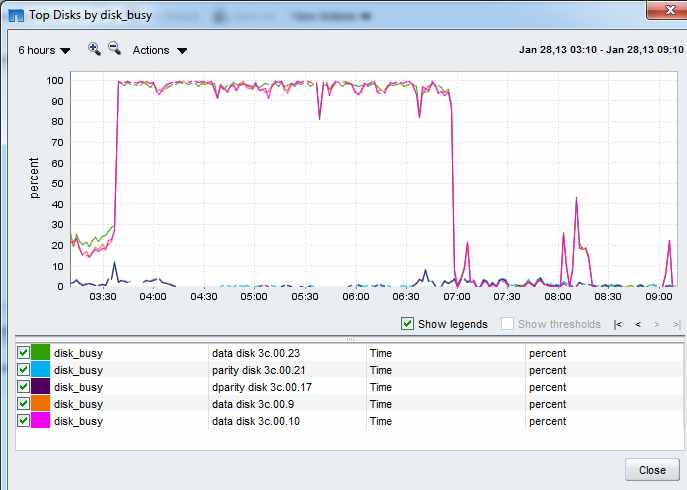
A re-allocate may be indicated since I seem to be seeing the same 3 data disks (9,10,23) in the spikes
On Jan 28, 2013, at 8:35 AM, Scott Eno s.eno@me.com wrote:
Shouldn't you be using version 3.2 with DFM 5.1?
On Jan 28, 2013, at 11:18 AM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
Anyone know why NMC 3.1 (DFM 5.1.0) sometimes reports "No data is currently available…"? and how to fix? Makes it even harder to track issues when the reporting tools fail. thanks
<nodatasata0.jpg>
On Jan 26, 2013, at 5:42 PM, Nicholas Bernstein nick@nicholasbernstein.com wrote:
Usually the ps will show you the process that's using the io indirectly, since its also probably using some CPU. Disk scrub, media scrub, reallocate_measure are just a couple things I can think off off the top of my head that are things that could cause read io.
Stats explain should be able to give you more info on that counter. Sorry this don't a more useful response, I'm on my phone and sick in bed. :/
-- Sent from my mobile device
On Jan 26, 2013, at 10:15 AM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
On Nick's advice I setup a job to log both wafltop and ps -c 1 once per minute - and we had a sustained sata0 disk busy from 5am-7am as reported by NMC. First question I have from wafltop show is - what is the first row (sata0::file i/o) reporting ? What could be the source of these 28907 non-volume specific Read IOs?
Application MB Total MB Read(STD) MB Write(STD) Read IOs(STD) Write IOs(STD) ----------- -------- ------------ ------------- ------------- -------------- sata0::file i/o: 5860 5830 30 28907 0sata0:backup:nfsv3: 608 0 608 31 0
I'm just starting to go through the data
aggr status Aggr State Status Options sata0 online raid_dp, aggr nosnap=on, raidsize=12 64-bit aggr2 online raid_dp, aggr nosnap=on, raidsize=19 64-bit aggr1 online raid_dp, aggr root, nosnap=on, raidsize=14 32-bit na04*> df -Ah Aggregate total used avail capacity aggr1 13TB 11TB 1431GB 89% aggr2 19TB 14TB 5305GB 74% sata0 27TB 19TB 8027GB 72%
<sataIOPSJan26.jpeg>
thanks
On Jan 25, 2013, at 5:33 PM, Nicholas Bernstein nick@nicholasbernstein.com wrote:
Try doing a 'ps -c 1' or a wafltop show (double check the syntax) while you're getting the spike; those will probably help you narrow down the processes that are using your disks. Both are priv set advanced/diag commands.
Nick
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
{kind=link}

That doesnt make sense.
They would ALWAYS be busy.
Disk statistics from statit would help..still.
On Mon, Jan 28, 2013 at 9:17 AM, Fletcher Cocquyt fcocquyt@stanford.eduwrote:
Thanks Scott - upgraded to 3.2 - no issues - this list is such a great resource
A re-allocate may be indicated since I seem to be seeing the same 3 data disks (9,10,23) in the spikes
On Jan 28, 2013, at 8:35 AM, Scott Eno s.eno@me.com wrote:
Shouldn't you be using version 3.2 with DFM 5.1?
On Jan 28, 2013, at 11:18 AM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
Anyone know why NMC 3.1 (DFM 5.1.0) sometimes reports "No data is currently available…"? and how to fix? Makes it even harder to track issues when the reporting tools fail. thanks
<nodatasata0.jpg>
On Jan 26, 2013, at 5:42 PM, Nicholas Bernstein < nick@nicholasbernstein.com> wrote:
Usually the ps will show you the process that's using the io indirectly, since its also probably using some CPU. Disk scrub, media scrub, reallocate_measure are just a couple things I can think off off the top of my head that are things that could cause read io.
Stats explain should be able to give you more info on that counter. Sorry this don't a more useful response, I'm on my phone and sick in bed. :/
-- Sent from my mobile device
On Jan 26, 2013, at 10:15 AM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
On Nick's advice I setup a job to log both wafltop and ps -c 1 once per minute - and we had a sustained sata0 disk busy from 5am-7am as reported by NMC. First question I have from wafltop show is - what is the first row (sata0::file i/o) reporting ? What could be the source of these 28907 non-volume specific Read IOs?
Application MB Total MB Read(STD) MB Write(STD) Read IOs(STD)Write IOs(STD) ----------- -------- ------------ ------------- -------------
sata0::file i/o: 5860 5830 30 28907 0sata0:backup:nfsv3: 608 0 608 31 0
I'm just starting to go through the data
aggr status Aggr State Status Options sata0 online raid_dp, aggr nosnap=on, raidsize=12 64-bit aggr2 online raid_dp, aggr nosnap=on, raidsize=19 64-bit aggr1 online raid_dp, aggr root, nosnap=on, raidsize=14 32-bit na04*> df -Ah Aggregate total used avail capacity aggr1 13TB 11TB 1431GB 89% aggr2 19TB 14TB 5305GB 74% sata0 27TB 19TB 8027GB 72%
<sataIOPSJan26.jpeg>
thanks
On Jan 25, 2013, at 5:33 PM, Nicholas Bernstein < nick@nicholasbernstein.com> wrote:
Try doing a 'ps -c 1' or a wafltop show (double check the syntax) while you're getting the spike; those will probably help you narrow down the processes that are using your disks. Both are priv set advanced/diag commands.
Nick
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
{kind=link}

So it looks like it is all read i/o Could you be running into a heavily deduped blocks in a 'sparse' database.
Jack Sent from my Verizon Wireless BlackBerry
-----Original Message----- From: Jeff Mohler speedtoys.racing@gmail.com Sender: toasters-bounces@teaparty.net Date: Mon, 28 Jan 2013 09:28:27 To: Fletcher Cocquytfcocquyt@stanford.edu Cc: toasters@teaparty.net Liststoasters@teaparty.net Subject: Re: Aggregate Disk Busy 100% with volume IOPS low
_______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters

The consistent spike day to day makes me think something is scheduled.. like a nightly SIS update. I agree that the hot disk issue is separate. If you redistributed the data, the spike probably won't go away, it'll affect more disks and maybe have a shorter time span.
Brian
On Mon, Jan 28, 2013 at 2:39 PM, Jack Lyons jack1729@gmail.com wrote:
So it looks like it is all read i/o Could you be running into a heavily deduped blocks in a 'sparse' database.
Jack Sent from my Verizon Wireless BlackBerry
-----Original Message----- From: Jeff Mohler speedtoys.racing@gmail.com Sender: toasters-bounces@teaparty.net Date: Mon, 28 Jan 2013 09:28:27 To: Fletcher Cocquytfcocquyt@stanford.edu Cc: toasters@teaparty.net Liststoasters@teaparty.net Subject: Re: Aggregate Disk Busy 100% with volume IOPS low
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
Once we disabled the reallocate measure and dedup jobs the spikes disappeared. The dedup job was scheduled quite a bit earlier than when the IO spikes showed up. Plus we did not notice an issue until we added just a bit more IO with app (oracle) or a reallocate measure. None of the (external or internal) tools could tell us directly what the source of the IO was.
thanks
On Jan 26, 2013, at 5:42 PM, Nicholas Bernstein nick@nicholasbernstein.com wrote:
Usually the ps will show you the process that's using the io indirectly, since its also probably using some CPU. Disk scrub, media scrub, reallocate_measure are just a couple things I can think off off the top of my head that are things that could cause read io.
Stats explain should be able to give you more info on that counter. Sorry this don't a more useful response, I'm on my phone and sick in bed. :/
-- Sent from my mobile device
On Jan 26, 2013, at 10:15 AM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
On Nick's advice I setup a job to log both wafltop and ps -c 1 once per minute - and we had a sustained sata0 disk busy from 5am-7am as reported by NMC. First question I have from wafltop show is - what is the first row (sata0::file i/o) reporting ? What could be the source of these 28907 non-volume specific Read IOs?
Application MB Total MB Read(STD) MB Write(STD) Read IOs(STD) Write IOs(STD) ----------- -------- ------------ ------------- ------------- -------------- sata0::file i/o: 5860 5830 30 28907 0sata0:backup:nfsv3: 608 0 608 31 0
I'm just starting to go through the data
aggr status Aggr State Status Options sata0 online raid_dp, aggr nosnap=on, raidsize=12 64-bit aggr2 online raid_dp, aggr nosnap=on, raidsize=19 64-bit aggr1 online raid_dp, aggr root, nosnap=on, raidsize=14 32-bit na04*> df -Ah Aggregate total used avail capacity aggr1 13TB 11TB 1431GB 89% aggr2 19TB 14TB 5305GB 74% sata0 27TB 19TB 8027GB 72%
<sataIOPSJan26.jpeg>
thanks
On Jan 25, 2013, at 5:33 PM, Nicholas Bernstein nick@nicholasbernstein.com wrote:
Try doing a 'ps -c 1' or a wafltop show (double check the syntax) while you're getting the spike; those will probably help you narrow down the processes that are using your disks. Both are priv set advanced/diag commands.
Nick

There might be a way by checking sis object in the netapp api.
https://communities.netapp.com/servlet/JiveServlet/previewBody/1044-102-2-75...
Tracking those stats might give you, and the rest of us, an idea of the impact of sis jobs. Kinda useless after the fact, but it may help in the future.
-Blake
On Mon, Feb 4, 2013 at 8:40 AM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
Once we disabled the reallocate measure and dedup jobs the spikes disappeared. The dedup job was scheduled quite a bit earlier than when the IO spikes showed up. Plus we did not notice an issue until we added just a bit more IO with app (oracle) or a reallocate measure. None of the (external or internal) tools could tell us directly what the source of the IO was.
thanks
On Jan 26, 2013, at 5:42 PM, Nicholas Bernstein nick@nicholasbernstein.com wrote:
Usually the ps will show you the process that's using the io indirectly, since its also probably using some CPU. Disk scrub, media scrub, reallocate_measure are just a couple things I can think off off the top of my head that are things that could cause read io.
Stats explain should be able to give you more info on that counter. Sorry this don't a more useful response, I'm on my phone and sick in bed. :/
-- Sent from my mobile device
On Jan 26, 2013, at 10:15 AM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
On Nick's advice I setup a job to log both wafltop and ps -c 1 once per minute - and we had a sustained sata0 disk busy from 5am-7am as reported by NMC. First question I have from wafltop show is - what is the first row (sata0::file i/o) reporting ? What could be the source of these 28907 non-volume specific Read IOs?
Application MB Total MB Read(STD) MB Write(STD) Read IOs(STD)Write IOs(STD) ----------- -------- ------------ ------------- -------------
sata0::file i/o: 5860 5830 30 289070 sata0:backup:nfsv3: 608 0 608 31 0
I'm just starting to go through the data
aggr status Aggr State Status Options sata0 online raid_dp, aggr nosnap=on, raidsize=12 64-bit aggr2 online raid_dp, aggr nosnap=on, raidsize=19 64-bit aggr1 online raid_dp, aggr root, nosnap=on, raidsize=14 32-bit na04*> df -Ah Aggregate total used avail capacity aggr1 13TB 11TB 1431GB 89% aggr2 19TB 14TB 5305GB 74% sata0 27TB 19TB 8027GB 72%
<sataIOPSJan26.jpeg>
thanks
On Jan 25, 2013, at 5:33 PM, Nicholas Bernstein nick@nicholasbernstein.com wrote:
Try doing a 'ps -c 1' or a wafltop show (double check the syntax) while you're getting the spike; those will probably help you narrow down the processes that are using your disks. Both are priv set advanced/diag commands.
Nick
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters

Figured I would send this out and see if anyway has experienced this.
System manager 2.1 running on windows xp and or 7 (multiple windows boxes) and I get the same issue described below.
On multiple filers DOT 8.1.x 7-mode, I see under the disks Icon in system manager (version 2.1), LOTS of disks that show up as broken. My system shows up as multi-path HA, and I have run "storage show disk -p" and all disks are multi-pathed; sysconfig -r all good......
I know in former versions of filerview, you could get ghosting of volumes that were offline, but the filerview showed other..
yeah, I know, it's all about the console..... I have a case open with support and he seemed dumbfounded as well.
Thanks everyone..

We see the same problem. Apparently a bug when you run system manager 2.1 and have DOT 8.1.
You either have to revert back to system manager 2.0 or upgrade to DOT 8.1.1 or later.
-Charles
-----Original Message----- From: toasters-bounces@teaparty.net [mailto:toasters-bounces@teaparty.net] On Behalf Of Klise, Steve Sent: Monday, February 04, 2013 4:42 PM To: toasters@teaparty.net Subject: something strange with system manager 2.1
Figured I would send this out and see if anyway has experienced this.
System manager 2.1 running on windows xp and or 7 (multiple windows boxes) and I get the same issue described below.
On multiple filers DOT 8.1.x 7-mode, I see under the disks Icon in system manager (version 2.1), LOTS of disks that show up as broken. My system shows up as multi-path HA, and I have run "storage show disk -p" and all disks are multi-pathed; sysconfig -r all good......
I know in former versions of filerview, you could get ghosting of volumes that were offline, but the filerview showed other..
yeah, I know, it's all about the console..... I have a case open with support and he seemed dumbfounded as well.
Thanks everyone..
_______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
Thanks Charles.
-----Original Message----- From: Charles H. Kruger [mailto:ck@Princeton.EDU] Sent: Monday, February 04, 2013 1:48 PM To: Klise, Steve; toasters@teaparty.net Subject: RE: something strange with system manager 2.1
We see the same problem. Apparently a bug when you run system manager 2.1 and have DOT 8.1.
You either have to revert back to system manager 2.0 or upgrade to DOT 8.1.1 or later.
-Charles
-----Original Message----- From: toasters-bounces@teaparty.net [mailto:toasters-bounces@teaparty.net] On Behalf Of Klise, Steve Sent: Monday, February 04, 2013 4:42 PM To: toasters@teaparty.net Subject: something strange with system manager 2.1
Figured I would send this out and see if anyway has experienced this.
System manager 2.1 running on windows xp and or 7 (multiple windows boxes) and I get the same issue described below.
On multiple filers DOT 8.1.x 7-mode, I see under the disks Icon in system manager (version 2.1), LOTS of disks that show up as broken. My system shows up as multi-path HA, and I have run "storage show disk -p" and all disks are multi-pathed; sysconfig -r all good......
I know in former versions of filerview, you could get ghosting of volumes that were offline, but the filerview showed other..
yeah, I know, it's all about the console..... I have a case open with support and he seemed dumbfounded as well.
Thanks everyone..
_______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters

I had this same issue show up at my customer as well. Somebody loaded System Manager 2.1 and all of the disks show as broken. When they look at everything in a previous version all is well.
Can you send me the NetApp support ticket so that I can track or add on to the support visibility?
Thanks,
Wayne
-----Original Message----- From: toasters-bounces@teaparty.net [mailto:toasters-bounces@teaparty.net] On Behalf Of Klise, Steve Sent: Monday, February 04, 2013 3:55 PM To: 'Charles H. Kruger'; 'toasters@teaparty.net' Subject: RE: something strange with system manager 2.1
Thanks Charles.
-----Original Message----- From: Charles H. Kruger [mailto:ck@Princeton.EDU] Sent: Monday, February 04, 2013 1:48 PM To: Klise, Steve; toasters@teaparty.net Subject: RE: something strange with system manager 2.1
We see the same problem. Apparently a bug when you run system manager 2.1 and have DOT 8.1.
You either have to revert back to system manager 2.0 or upgrade to DOT 8.1.1 or later.
-Charles
-----Original Message----- From: toasters-bounces@teaparty.net [mailto:toasters-bounces@teaparty.net] On Behalf Of Klise, Steve Sent: Monday, February 04, 2013 4:42 PM To: toasters@teaparty.net Subject: something strange with system manager 2.1
Figured I would send this out and see if anyway has experienced this.
System manager 2.1 running on windows xp and or 7 (multiple windows boxes) and I get the same issue described below.
On multiple filers DOT 8.1.x 7-mode, I see under the disks Icon in system manager (version 2.1), LOTS of disks that show up as broken. My system shows up as multi-path HA, and I have run "storage show disk -p" and all disks are multi-pathed; sysconfig -r all good......
I know in former versions of filerview, you could get ghosting of volumes that were offline, but the filerview showed other..
yeah, I know, it's all about the console..... I have a case open with support and he seemed dumbfounded as well.
Thanks everyone..
_______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
_______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
and for what its worth, creating an AGGR is an issue via SysMgr. I do from the console, so it's not biggie but sucks for the gui guys. Maybe also related.
-----Original Message----- From: Sandy, Wayne [mailto:Wayne.Sandy@netapp.com] Sent: Monday, February 04, 2013 2:32 PM To: Klise, Steve; 'Charles H. Kruger'; 'toasters@teaparty.net' Subject: RE: something strange with system manager 2.1
I had this same issue show up at my customer as well. Somebody loaded System Manager 2.1 and all of the disks show as broken. When they look at everything in a previous version all is well.
Can you send me the NetApp support ticket so that I can track or add on to the support visibility?
Thanks,
Wayne
-----Original Message----- From: toasters-bounces@teaparty.net [mailto:toasters-bounces@teaparty.net] On Behalf Of Klise, Steve Sent: Monday, February 04, 2013 3:55 PM To: 'Charles H. Kruger'; 'toasters@teaparty.net' Subject: RE: something strange with system manager 2.1
Thanks Charles.
-----Original Message----- From: Charles H. Kruger [mailto:ck@Princeton.EDU] Sent: Monday, February 04, 2013 1:48 PM To: Klise, Steve; toasters@teaparty.net Subject: RE: something strange with system manager 2.1
We see the same problem. Apparently a bug when you run system manager 2.1 and have DOT 8.1.
You either have to revert back to system manager 2.0 or upgrade to DOT 8.1.1 or later.
-Charles
-----Original Message----- From: toasters-bounces@teaparty.net [mailto:toasters-bounces@teaparty.net] On Behalf Of Klise, Steve Sent: Monday, February 04, 2013 4:42 PM To: toasters@teaparty.net Subject: something strange with system manager 2.1
Figured I would send this out and see if anyway has experienced this.
System manager 2.1 running on windows xp and or 7 (multiple windows boxes) and I get the same issue described below.
On multiple filers DOT 8.1.x 7-mode, I see under the disks Icon in system manager (version 2.1), LOTS of disks that show up as broken. My system shows up as multi-path HA, and I have run "storage show disk -p" and all disks are multi-pathed; sysconfig -r all good......
I know in former versions of filerview, you could get ghosting of volumes that were offline, but the filerview showed other..
yeah, I know, it's all about the console..... I have a case open with support and he seemed dumbfounded as well.
Thanks everyone..
_______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
_______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
Anyone out there using storageGRID? Good, bad, ugly? We're looking to consolidate a few PB of images.. Just wondering if anyone out there has an opinion on these devices. Were doing a dog and pony show to see what it does. Seems very filerview'ish but scales like a beast.
Thanks
Garbage Collector III
Notepad, vi.... :)
Sent from my iPhone
On Jan 25, 2013, at 4:47 PM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
We are still seeing physical disk IO (95% reads) spikes without any volume level IO. I'm trying to determine if its related to large file deletions or something else - I might have to go digging in the perfstats myself. Are there any tools available to us to pick apart and analyze perfstats?
<sataspike.jpg>
thanks
On Jan 24, 2013, at 4:24 AM, "Uddhav Regmi" uregmi111@gmail.com wrote:
That is normal…. I do see those…..
Just make sure, that network data – are not heavily IN at that time
From: toasters-bounces@teaparty.net [mailto:toasters-bounces@teaparty.net] On Behalf Of Fletcher Cocquyt Sent: Thursday, January 24, 2013 12:28 AM To: toasters@teaparty.net Lists Subject: Aggregate Disk Busy 100% with volume IOPS low
3270 cluster, OnTAP 8.1-7mode
We are investigating a SATA aggregate showing repeated 5am disk 100% busy spikes without its volumes showing any corresponding IOPS spike as reported by Netapp Management Console (NMC). The 5am disk busy spikes correlate with very high latency on volumes on a different SAS aggregate. These volumes host VMs which then timeout, some needing reboots. Today when I heard from Netapp support after reviewing my perfstat the engineer reported this is expected since NVRAM buffers are shared btw aggregates.
But when I dig further into the NMC stats I see the SATA aggregate disk busy actually corresponds to a DROP in IOPS on the 3 volumes hosted on the SATA aggregate - almost like some internal aggregate operations are starving out the external volume ops. I checked the snapshots (vol and aggr), snap mirror, dedup and none of the usual suspects were running.
When I look at the NMC throughput graphs and switch on the legend - it shows a 5am READ blocks/sec spike corresponding perfectly to the disk busy.
Where are these AGGR level READ operations coming from that are missing from the constituent volume IOPS, and in fact seem to be starving out volume level IO?
I don't see much in the messages log, but will check the rest of the logs for internal type OPS
thanks for any insight
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters

Fletcher Cocquyt wrote:
We are still seeing physical disk IO (95% reads) spikes without any volume level IO. I'm trying to determine if its related to large file deletions or something else - I might have to go digging in the perfstats myself. Are there any tools available to us to pick apart and analyze perfstats?
There exists a NetApp tool which assists in interpretation of perfstat outputs, which often consist of 100s of MB of textual data. The LatX Web app. It's by no means an expert tool which somehow magically tells you what's going on. It parses, divides up, and visualizes the perfstat output to make it much easier to overview when looking at a system
AFAIK to have access to LatX, you need to have an account at support.netapp.com either as a NetApp employee or have status as a NetApp partner. I don't know of any way you as an "ordinary" customer can gain access to LatX by youself to use it at will.
Of course correctly interpreting perfstat output with or without LatX takes a great amount of knowledge about the inner workings of ONTAP -- stuff that has no easily accessible documentation.
NetApp normally don't even mention to customers about ONTAP Kernel Domains (serial Kahuna, parallel Kahuna aka wafl_exempt etc), but the fact remains they are crucial to understanding the bottlenecks inside a 7-mode Filer under high pressure. When reading perfstat output you really must understand these things or you'll stand little chance of drawing any useful conclusions
/M
A perfstat is HUGE.
But its just pre-data, and then iterative data.
So..when you look at it like that, its a small amount of data repeated many times.
People would ask me how I view perfstats..and well, notepad and vi both work.
Tools for perfstats dont tell anything, they just lead you to command output.
Im curious in the disk statistics part of statit during this period.
On Sat, Jan 26, 2013 at 10:54 AM, Michael Bergman < michael.bergman@ericsson.com> wrote:
Fletcher Cocquyt wrote:
We are still seeing physical disk IO (95% reads) spikes without any volume level IO. I'm trying to determine if its related to large file deletions or something else - I might have to go digging in the perfstats myself. Are there any tools available to us to pick apart and analyze perfstats?
There exists a NetApp tool which assists in interpretation of perfstat outputs, which often consist of 100s of MB of textual data. The LatX Web app. It's by no means an expert tool which somehow magically tells you what's going on. It parses, divides up, and visualizes the perfstat output to make it much easier to overview when looking at a system
AFAIK to have access to LatX, you need to have an account at support.netapp.com either as a NetApp employee or have status as a NetApp partner. I don't know of any way you as an "ordinary" customer can gain access to LatX by youself to use it at will.
Of course correctly interpreting perfstat output with or without LatX takes a great amount of knowledge about the inner workings of ONTAP -- stuff that has no easily accessible documentation.
NetApp normally don't even mention to customers about ONTAP Kernel Domains (serial Kahuna, parallel Kahuna aka wafl_exempt etc), but the fact remains they are crucial to understanding the bottlenecks inside a 7-mode Filer under high pressure. When reading perfstat output you really must understand these things or you'll stand little chance of drawing any useful conclusions
/M
Michael Bergman Sr Systems Analyst / Storage Architect michael.bergman@ericsson.com Engineering Hub Stockholm Phone +46 10 7152945 Service Delivery, Engineering EMEA N SMS/MMS +46 70 5480835 Ericsson Torshamnsg 33, 16480 Sthlm, Sweden -- This communication is confidential. We only send and receive email on the basis of the terms set out at www.ericsson.com/email_**disclaimerhttp://www.ericsson.com/email_disclaimer
______________________________**_________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/**mailman/listinfo/toastershttp://www.teaparty.net/mailman/listinfo/toasters
-
 Blake Golliher
Blake Golliher -
 Brian Beaulieu
Brian Beaulieu -
 Charles H. Kruger
Charles H. Kruger -
 Fletcher Cocquyt
Fletcher Cocquyt -
 Jack Lyons
Jack Lyons -
 Jeff Mohler
Jeff Mohler -
 Klise, Steve
Klise, Steve -
 Michael Bergman
Michael Bergman -
 Nicholas Bernstein
Nicholas Bernstein -
 Sandy, Wayne
Sandy, Wayne -
 Scott Eno
Scott Eno -
 Timothy Naple
Timothy Naple -
 Uddhav Regmi
Uddhav Regmi