
What about other IO on the aggregate? Any other volume activity (snaps, resize)
I feel your pain. I've had one single VM cause IO spikes and thus latency. I had this happen when I moved the VM from an NFS datastore to a VMFS datastore to get more IO potential. Well, that extra IO was too much of a piece of the pie.
The other night I had all NFS/CIFS IO completely stop for a couple of minutes during a volume resize.
I love NFS+VMWare+NetApp but sometimes I hate it as well.
Brian

Running a perfstat now for netapp support and monitoring the disk busy % We seem to have one disk (3a.01) noticeably busier than the rest of the 95 disks in the aggregate Is this a potential hotspot? aggregate re-allocate indicated here?
thanks
On Jan 17, 2013, at 8:24 AM, Brian Beaulieu brian.beaulieu@gmail.com wrote:
What about other IO on the aggregate? Any other volume activity (snaps, resize)
I feel your pain. I've had one single VM cause IO spikes and thus latency. I had this happen when I moved the VM from an NFS datastore to a VMFS datastore to get more IO potential. Well, that extra IO was too much of a piece of the pie.
The other night I had all NFS/CIFS IO completely stop for a couple of minutes during a volume resize.
I love NFS+VMWare+NetApp but sometimes I hate it as well.
Brian _______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
{kind=link}
Resending with smaller (lower quality jpeg) to fit in this list's 100K limit
On Jan 17, 2013, at 9:18 AM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
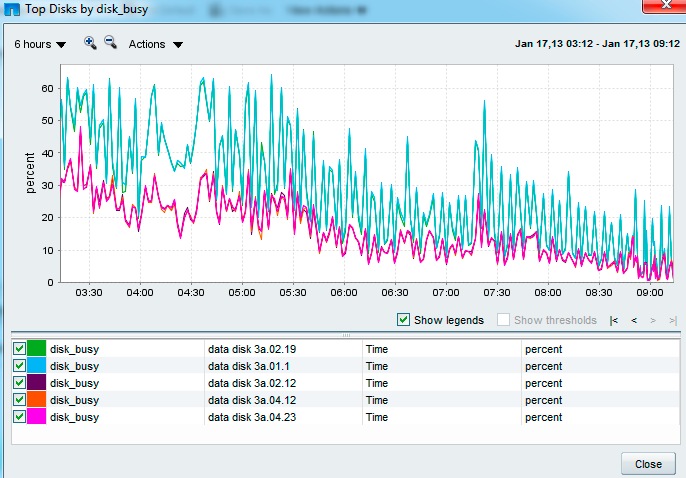
Running a perfstat now for netapp support and monitoring the disk busy % We seem to have one disk (3a.01) noticeably busier than the rest of the 95 disks in the aggregate Is this a potential hotspot? aggregate re-allocate indicated here?
thanks
<PastedGraphic-14.png>
On Jan 17, 2013, at 8:24 AM, Brian Beaulieu brian.beaulieu@gmail.com wrote:
What about other IO on the aggregate? Any other volume activity (snaps, resize)
I feel your pain. I've had one single VM cause IO spikes and thus latency. I had this happen when I moved the VM from an NFS datastore to a VMFS datastore to get more IO potential. Well, that extra IO was too much of a piece of the pie.
The other night I had all NFS/CIFS IO completely stop for a couple of minutes during a volume resize.
I love NFS+VMWare+NetApp but sometimes I hate it as well.
Brian _______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
{kind=link}
attempt #3
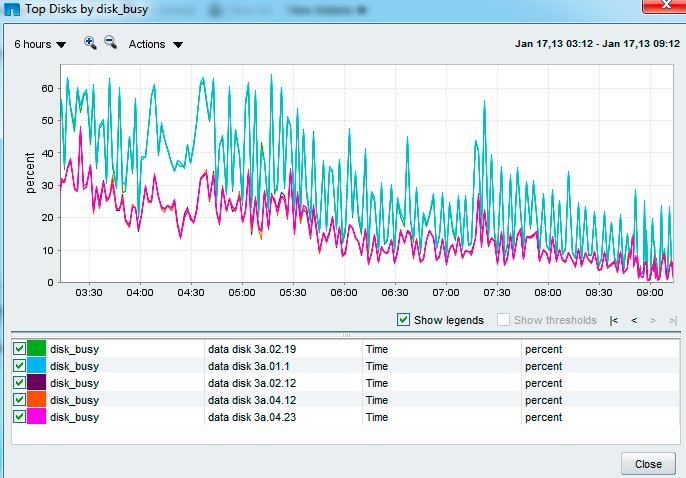
Running a perfstat now for netapp support and monitoring the disk busy % We seem to have one disk (3a.01) noticeably busier than the rest of the 95 disks in the aggregate Is this a potential hotspot? aggregate re-allocate indicated here?
thanks
<PastedGraphic-14.png>
On Jan 17, 2013, at 8:24 AM, Brian Beaulieu brian.beaulieu@gmail.com wrote:
What about other IO on the aggregate? Any other volume activity (snaps, resize)
I feel your pain. I've had one single VM cause IO spikes and thus latency. I had this happen when I moved the VM from an NFS datastore to a VMFS datastore to get more IO potential. Well, that extra IO was too much of a piece of the pie.
The other night I had all NFS/CIFS IO completely stop for a couple of minutes during a volume resize.
I love NFS+VMWare+NetApp but sometimes I hate it as well.
Brian _______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
{kind=link}

Perhaps. Need iop count between that bust dlsk and a representative non busy one in the same raid group.
Or, a disk statistics snippet from a statit would be better. Yes. Better.
Sent from my iPhone
On Jan 17, 2013, at 5:22 PM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
<diskbusy2.jpg> Resending with smaller (lower quality jpeg) to fit in this list's 100K limit
On Jan 17, 2013, at 9:18 AM, Fletcher Cocquyt fcocquyt@stanford.edu wrote:
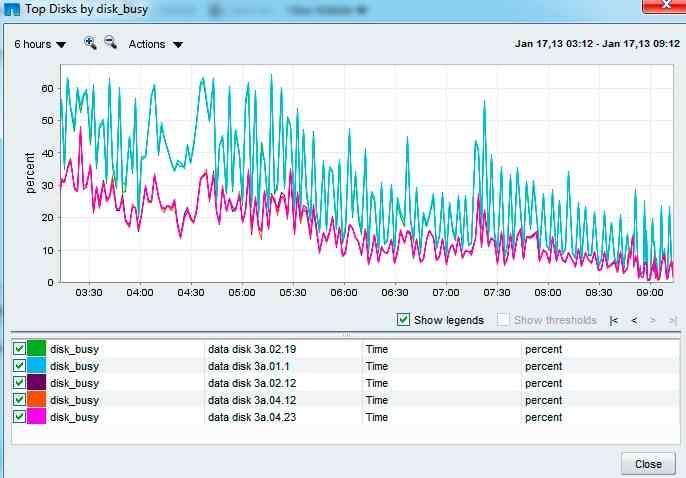
Running a perfstat now for netapp support and monitoring the disk busy % We seem to have one disk (3a.01) noticeably busier than the rest of the 95 disks in the aggregate Is this a potential hotspot? aggregate re-allocate indicated here?
thanks
<PastedGraphic-14.png>
On Jan 17, 2013, at 8:24 AM, Brian Beaulieu brian.beaulieu@gmail.com wrote:
What about other IO on the aggregate? Any other volume activity (snaps, resize)
I feel your pain. I've had one single VM cause IO spikes and thus latency. I had this happen when I moved the VM from an NFS datastore to a VMFS datastore to get more IO potential. Well, that extra IO was too much of a piece of the pie.
The other night I had all NFS/CIFS IO completely stop for a couple of minutes during a volume resize.
I love NFS+VMWare+NetApp but sometimes I hate it as well.
Brian _______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters

I have been fighting these issues since last September. For our environment it has boiled down to drinking the kool-aid re: SATA/PAM cost savings. The SATA disks just can't crank out the IOPS that the vmware environment demands, and the PAMII (256G) isn't helping (official response from NetApp engineers). Right now I have 18TB of SATA disk space devoted to 2TB of vmware, just to get the spindles needed, but still seeing the "stuck" CP which ends up making the FAS3140 stop responding to NFS/CIFS/iSCSI out all interfaces.
We're preparing to move vmware to four DS2246 shelves with 10k 600GB disks, but now seeing that folks are having these issues with 15k disks is very concerning.
We're VMware + NFS too.
On Jan 17, 2013, at 11:24 AM, Brian Beaulieu brian.beaulieu@gmail.com wrote:
What about other IO on the aggregate? Any other volume activity (snaps, resize)
I feel your pain. I've had one single VM cause IO spikes and thus latency. I had this happen when I moved the VM from an NFS datastore to a VMFS datastore to get more IO potential. Well, that extra IO was too much of a piece of the pie.
The other night I had all NFS/CIFS IO completely stop for a couple of minutes during a volume resize.
I love NFS+VMWare+NetApp but sometimes I hate it as well.
Brian _______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
-
 Brian Beaulieu
Brian Beaulieu -
 Fletcher Cocquyt
Fletcher Cocquyt -
 Jeff Mohler
Jeff Mohler -
 Scott Eno
Scott Eno