
Greetings,
We upgraded a pair of 6080s and 6040s from 7.3.3P5 to 7.3.5.1P4 at the first of the year. Within 1 hour of the upgrade, our OpenNMS server started getting timeouts for SNMP polling. We had ~130 per head for the 6080s in the next 2 days. We had 0 in the prior 2 months that I checked. We also noticed the average CPU load for each head went from ~40% to close to 60% utilization comparing December to January. Anytime the cluster is in a failover mode, we get quite a few customer complaints due to slowness. While I can't say for certain we did not have this slowness before, none of us remember any complaints when the cluster was failed before. Obviously trying to run 120% utilization on 1 filer instead of 80% will cause this issue :-) The 6040 cluster did not give the polling errors, but it looks like the CPU load is higher on them also. The load is usually low enough to gracefully cover a cluster failover.
I've had a case opened since the first of the year and it looks like we are now out of options and ideas with no explanation or resolution. At this point our plan is to roll back to the 7.3.3P5 OS since it seemed to behave better. Since there is no identifiable problem or solution, it makes us unwilling to jump to a newer OS since we have no reason to believe the issue isn't inherited by later revisions. Rolling back to a known good OS seems to make the most sense. We will roll the 6080 cluster back first and see how it works out before we roll the 6040 cluster.
My question to the group is whether anyone else has had a similar issue but did jump to a newer OnTap release that fixed the issues? The vast majority of our data access is via nfs from RHEL5 clients and servers.
Thanks,
Jeff

Hi Jeff,
I don't have an answer to your question, which is basically: what changed between 7.3.3P5 and 7.3.5.1P4?
But I'm hoping that the following offers a clue.
Perhaps the Kahuna domain on your 6000s is pegged? As I understand it (and my understanding is fuzzy, so take this with salt), ONTAP is gradually becoming more and more multi-threaded with each release ... but in the 7.3.x train, numerous key processes, including low-level WAFL process, plus management processes like the SNMP daemon (and the daemon which services the CLI, plus NDMP and the de-dup process and possibly others) are still single-threaded /and/ all live together in one process 'domain' nicknamed Kahuna, which ends up occupying a single CPU. [Apparently, a 'domain' hosts multiple processes/daemons, and 'domains' get assigned to a single core. Or something like that -- I may be confused on the details.]
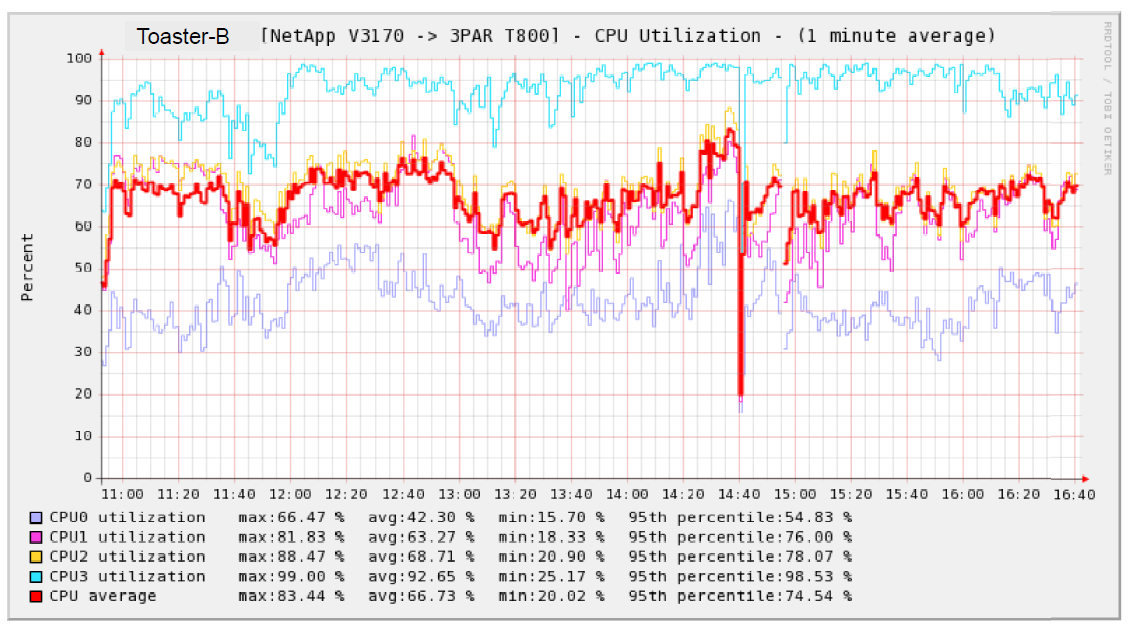
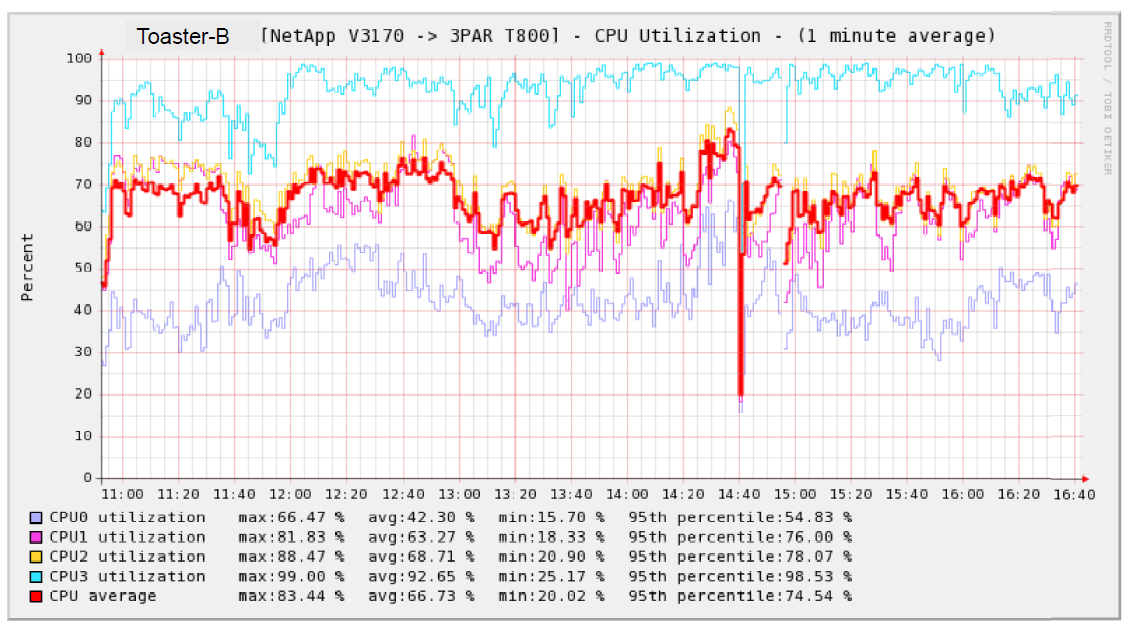
Here you can see a trending chart of the 4 cores in a v3170. On this box, Kahuna lives on CPU3. Notice that CPU3 is pegged or nearly so. And if you stare carefully at this, you'll see that as CPU3 utilization climbs, the utilization on the other processors /drops/ ... as I understand it, this is because daemons running on those other cores block, waiting for a WAFL transaction (living in Kahuna, i.e. running on CPU3) to complete. So, /average/ CPU utilization across all four cores isn't bad ... ~67% ... but /average/ utilization doesn't matter: what matters is the utilization of the processor hosting Kahuna: when that starts to peg, we see performance issues on clients (SMB, NFS, and iSCSI: WAFL transactions getting slowed down), SNMP check timeouts from Nagios, sluggish CLI performance, stalled NDMP jobs, crawling de-dupes. https://vishnu.fhcrc.org/toasters/ONTAP-CPU-Utilization-Illustrating-Kahuna-...
What to do? Well, we've been trying to jigger NDMP jobs and de-dup jobs to run sequentially rather than in parallel with each other (apparently, a single NDMP or a single de-dup process can consume a CPU, so trying to run more than one at a time is suboptimal) and trying to make sure that both stop before the users start arriving -- perhaps something similar would buy your 6000s, or, more precisely, Kahuna on your 6000s, more breathing room. As I understand it, 8.0 makes another substantial step forward, in terms of multi-threading. And 8.1 either finishes the job or comes close to implementing multi-threading in every process. We've moved to 8.0 on other boxes, but not on the one above [The box above is running 7.3.5.1Psomething]
If the model I'm offering applies to your situation, then the interesting questions become: (a) Did ONTAP introduce any multi-threading/single-threading changes between 7.3.3P5 and 7.3.5.1P4 which might have put more pressure on Kahuna in your installation? or (b) Did other changes occur simultaneously with your upgrade, such that in fact migrating back to 7.3.3P5 wouldn't help at all ... perhaps the number of bits on de-duped volumes grew substantially around the time of the upgrade, such that your de-dupe processes are now running throughout the day? Or your backup schedule changed, such that NDMP jobs are now running through the day?
Or perhaps the model I'm offering doesn't apply to your installation.
hth,
--sk
Stuart Kendrick FHCRC
On 4/25/2012 2:55 PM, Jeff Cleverley wrote:
Greetings,
We upgraded a pair of 6080s and 6040s from 7.3.3P5 to 7.3.5.1P4 at the first of the year. Within 1 hour of the upgrade, our OpenNMS server started getting timeouts for SNMP polling. We had ~130 per head for the 6080s in the next 2 days. We had 0 in the prior 2 months that I checked. We also noticed the average CPU load for each head went from ~40% to close to 60% utilization comparing December to January. Anytime the cluster is in a failover mode, we get quite a few customer complaints due to slowness. While I can't say for certain we did not have this slowness before, none of us remember any complaints when the cluster was failed before. Obviously trying to run 120% utilization on 1 filer instead of 80% will cause this issue :-) The 6040 cluster did not give the polling errors, but it looks like the CPU load is higher on them also. The load is usually low enough to gracefully cover a cluster failover.
I've had a case opened since the first of the year and it looks like we are now out of options and ideas with no explanation or resolution. At this point our plan is to roll back to the 7.3.3P5 OS since it seemed to behave better. Since there is no identifiable problem or solution, it makes us unwilling to jump to a newer OS since we have no reason to believe the issue isn't inherited by later revisions. Rolling back to a known good OS seems to make the most sense. We will roll the 6080 cluster back first and see how it works out before we roll the 6040 cluster.
My question to the group is whether anyone else has had a similar issue but did jump to a newer OnTap release that fixed the issues? The vast majority of our data access is via nfs from RHEL5 clients and servers.
Thanks,
Jeff
{kind=link}
Stuart,
Thanks for the reply. My comments are below.
On Wed, Apr 25, 2012 at 6:18 PM, Stuart Kendrick skendric@fhcrc.org wrote:
Perhaps the Kahuna domain on your 6000s is pegged? As I understand it (and my understanding is fuzzy, so take this with salt), ONTAP is gradually becoming more and more multi-threaded with each release ... but in the 7.3.x train, numerous key processes, including low-level WAFL process, plus management processes like the SNMP daemon (and the daemon which services the CLI, plus NDMP and the de-dup process and possibly others) are still single-threaded /and/ all live together in one process 'domain' nicknamed Kahuna, which ends up occupying a single CPU. [Apparently, a 'domain' hosts multiple processes/daemons, and 'domains' get assigned to a single core. Or something like that -- I may be confused on the details.]
From what I know your understanding is pretty good. The Kahuna domain
processes have been getting broken out into smaller pieces to be more efficient with different releases. I believe at least 2 different performance analysis people have looked at perfstats and none have said it was pegged. I do see the CPUs on the second quad core being busier than the first core, and CPU8 usually busier than 5,6,and 7. This matches up with what you are saying.
Here you can see a trending chart of the 4 cores in a v3170. On this box, Kahuna lives on CPU3. Notice that CPU3 is pegged or nearly so. And if you stare carefully at this, you'll see that as CPU3 utilization climbs, the utilization on the other processors /drops/ ... as I understand it, this is because daemons running on those other cores block, waiting for a WAFL transaction (living in Kahuna, i.e. running on CPU3) to complete. So, /average/ CPU utilization across all four cores isn't bad ... ~67% ... but /average/ utilization doesn't matter: what matters is the utilization of the processor hosting Kahuna: when that starts to peg, we see performance issues on clients (SMB, NFS, and iSCSI: WAFL transactions getting slowed down), SNMP check timeouts from Nagios, sluggish CLI performance, stalled NDMP jobs, crawling de-dupes.
https://vishnu.fhcrc.org/toasters/ONTAP-CPU-Utilization-Illustrating-Kahuna-...
What to do? Well, we've been trying to jigger NDMP jobs and de-dup jobs to run sequentially rather than in parallel with each other (apparently, a single NDMP or a single de-dup process can consume a CPU, so trying to run more than one at a time is suboptimal) and trying to make sure that both stop before the users start arriving -- perhaps something similar would buy your 6000s, or, more precisely, Kahuna on your 6000s, more breathing room. As I understand it, 8.0 makes another substantial step forward, in terms of multi-threading. And 8.1 either finishes the job or comes close to implementing multi-threading in every process. We've moved to 8.0 on other boxes, but not on the one above [The box above is running 7.3.5.1Psomething]
These filers run pretty clean. We don't do any deduplication, there are no SnapMirrors, and nightly Snapvault backups are really the only things that run. I have thought about an 8.x install but need to look into it more. For years everyone I've ever spoken with at NetApp has said run 7x on the primary filers and 8x on the secondaries. Before I make the switch I need to find out more about what has changed to make it primary filer material. A downgrade back to 7x if something did not work out would be difficult to impossible once the upgrade is completed (64 bit aggregates, etc).
If the model I'm offering applies to your situation, then the interesting questions become: (a) Did ONTAP introduce any multi-threading/single-threading changes between 7.3.3P5 and 7.3.5.1P4 which might have put more pressure on Kahuna in your installation?
This is the million dollar question I have not been able to get an answer to. I have suspected some level of change to a multi-threading routine is causing the issue. We see more problems on the 8 CPU 6080 vs the 4 CPU 6040. It is almost like it has too many processors to work with and ends up thrashing somehow.
or (b) Did other changes occur simultaneously with your upgrade, such that in fact migrating back to 7.3.3P5 wouldn't help at all ... perhaps the number of bits on de-duped volumes grew substantially around the time of the upgrade, such that your de-dupe processes are now running throughout the day? Or your backup schedule changed, such that NDMP jobs are now running through the day?
The only changes made that morning (7am January 1st, nobody else was doing anything :-) ) was the OnTap upgrade and the diagnostics were upgraded from I believe 5.5 to 5.6.1. As mentioned above we don't do any deduplication and no backup schedules changed. I also know the filers were not significantly busier at 9am than they were at 7am.
Or perhaps the model I'm offering doesn't apply to your installation.
I think your model is fairly accurate. I did not do a perfstat before the upgrade so there isn't a good before and after comparison. There will definitely be one when I roll it back though :-)
Thanks,
Jeff
hth,
--sk
Stuart Kendrick FHCRC
On 4/25/2012 2:55 PM, Jeff Cleverley wrote:
Greetings,
We upgraded a pair of 6080s and 6040s from 7.3.3P5 to 7.3.5.1P4 at the first of the year. Within 1 hour of the upgrade, our OpenNMS server started getting timeouts for SNMP polling. We had ~130 per head for the 6080s in the next 2 days. We had 0 in the prior 2 months that I checked. We also noticed the average CPU load for each head went from ~40% to close to 60% utilization comparing December to January. Anytime the cluster is in a failover mode, we get quite a few customer complaints due to slowness. While I can't say for certain we did not have this slowness before, none of us remember any complaints when the cluster was failed before. Obviously trying to run 120% utilization on 1 filer instead of 80% will cause this issue :-) The 6040 cluster did not give the polling errors, but it looks like the CPU load is higher on them also. The load is usually low enough to gracefully cover a cluster failover.
I've had a case opened since the first of the year and it looks like we are now out of options and ideas with no explanation or resolution. At this point our plan is to roll back to the 7.3.3P5 OS since it seemed to behave better. Since there is no identifiable problem or solution, it makes us unwilling to jump to a newer OS since we have no reason to believe the issue isn't inherited by later revisions. Rolling back to a known good OS seems to make the most sense. We will roll the 6080 cluster back first and see how it works out before we roll the 6040 cluster.
My question to the group is whether anyone else has had a similar issue but did jump to a newer OnTap release that fixed the issues? The vast majority of our data access is via nfs from RHEL5 clients and servers.
Thanks,
Jeff
{kind=link}
My apologies if this ends up as a double post. The first was rich text and was held due to the size being too large.
Jeff
On Wed, Apr 25, 2012 at 11:34 PM, Jeff Cleverley jeff.cleverley@avagotech.com wrote:
Stuart,
Thanks for the reply. My comments are below.
Perhaps the Kahuna domain on your 6000s is pegged? As I understand it (and my understanding is fuzzy, so take this with salt), ONTAP is gradually becoming more and more multi-threaded with each release ... but in the 7.3.x train, numerous key processes, including low-level WAFL process, plus management processes like the SNMP daemon (and the daemon which services the CLI, plus NDMP and the de-dup process and possibly others) are still single-threaded /and/ all live together in one process 'domain' nicknamed Kahuna, which ends up occupying a single CPU. [Apparently, a 'domain' hosts multiple processes/daemons, and 'domains' get assigned to a single core. Or something like that -- I may be confused on the details.]
From what I know your understanding is pretty good. The Kahuna domain processes have been getting broken out into smaller pieces to be more efficient with different releases. I believe at least 2 different performance analysis people have looked at perfstats and none have said it was pegged. I do see the CPUs on the second quad core being busier than the first core, and CPU8 usually busier than 5,6,and 7. This matches up with what you are saying.
Here you can see a trending chart of the 4 cores in a v3170. On this box, Kahuna lives on CPU3. Notice that CPU3 is pegged or nearly so. And if you stare carefully at this, you'll see that as CPU3 utilization climbs, the utilization on the other processors /drops/ ... as I understand it, this is because daemons running on those other cores block, waiting for a WAFL transaction (living in Kahuna, i.e. running on CPU3) to complete. So, /average/ CPU utilization across all four cores isn't bad ... ~67% ... but /average/ utilization doesn't matter: what matters is the utilization of the processor hosting Kahuna: when that starts to peg, we see performance issues on clients (SMB, NFS, and iSCSI: WAFL transactions getting slowed down), SNMP check timeouts from Nagios, sluggish CLI performance, stalled NDMP jobs, crawling de-dupes. https://vishnu.fhcrc.org/toasters/ONTAP-CPU-Utilization-Illustrating-Kahuna-...
What to do? Well, we've been trying to jigger NDMP jobs and de-dup jobs to run sequentially rather than in parallel with each other (apparently, a single NDMP or a single de-dup process can consume a CPU, so trying to run more than one at a time is suboptimal) and trying to make sure that both stop before the users start arriving -- perhaps something similar would buy your 6000s, or, more precisely, Kahuna on your 6000s, more breathing room. As I understand it, 8.0 makes another substantial step forward, in terms of multi-threading. And 8.1 either finishes the job or comes close to implementing multi-threading in every process. We've moved to 8.0 on other boxes, but not on the one above [The box above is running 7.3.5.1Psomething]
These filers run pretty clean. We don't do any deduplication, there are no SnapMirrors, and nightly Snapvault backups are really the only things that run. I have thought about an 8.x install but need to look into it more. For years everyone I've ever spoken with at NetApp has said run 7x on the primary filers and 8x on the secondaries. Before I make the switch I need to find out more about what has changed to make it primary filer material. A downgrade back to 7x if something did not work out would be difficult to impossible once the upgrade is completed (64 bit aggregates, etc).
If the model I'm offering applies to your situation, then the interesting questions become: (a) Did ONTAP introduce any multi-threading/single-threading changes between 7.3.3P5 and 7.3.5.1P4 which might have put more pressure on Kahuna in your installation?
This is the million dollar question I have not been able to get an answer to. I have suspected some level of change to a multi-threading routine is causing the issue. We see more problems on the 8 CPU 6080 vs the 4 CPU 6040. It is almost like it has too many processors to work with and ends up thrashing somehow.
or (b) Did other changes occur simultaneously with your upgrade, such that in fact migrating back to 7.3.3P5 wouldn't help at all ... perhaps the number of bits on de-duped volumes grew substantially around the time of the upgrade, such that your de-dupe processes are now running throughout the day? Or your backup schedule changed, such that NDMP jobs are now running through the day?
The only changes made that morning (7am January 1st, nobody else was doing anything :-) ) was the OnTap upgrade and the diagnostics were upgraded from I believe 5.5 to 5.6.1. As mentioned above we don't do any deduplication and no backup schedules changed. I also know the filers were not significantly busier at 9am than they were at 7am.
Or perhaps the model I'm offering doesn't apply to your installation.
I think your model is fairly accurate. I did not do a perfstat before the upgrade so there isn't a good before and after comparison. There will definitely be one when I roll it back though :-)
Thanks,
Jeff
-- Jeff Cleverley Unix Systems Administrator 4380 Ziegler Road Fort Collins, Colorado 80525 970-288-4611
-
 Jeff Cleverley
Jeff Cleverley -
 Stuart Kendrick
Stuart Kendrick