
hi
i have a metro cluster (rather old) which is currently responding very slowly. 7-mode 8.1.4
there is only one aggregate per head, filled at around 72% one one head and 79% on the other head. attached is a statit and sysstat -x 1 from one head.
i see lots of partial stripes and only several full stripes. i assume this should mean not enough free space, which should imho not be a problem at my aggregates.
what is the correct procedure for performing a free space reallocation? i did: * stop all volume-reallocates * disable read_reallocation on all volumes * raid.lost_write.enable off * aggr options aggr0 resyncsnaptime 5 * reallocate start -A -o aggr0 * wait for finish of reallocate * aggr options aggr0 resyncsnaptime 60 * enable read_reallocation on all volumes * reenable all volume-level reallocates
my aggregates have options:
aggr options aggr0 root, diskroot, nosnap=off, raidtype=raid_dp, raidsize=20, ignore_inconsistent=off, snapmirrored=off, resyncsnaptime=60, fs_size_fixed=off, snapshot_autodelete=on, lost_write_protect=on, ha_policy=cfo, hybrid_enabled=off, percent_snapshot_space=5%, free_space_realloc=off
any advice? josef

Are you write latency troubled, or read latency troubled?
I don't see free space frag as a huge issue, as lightly loaded as the spindles report to be.
_________________________________Jeff MohlerTech Yahoo, Storage Architect, Principal(831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 11:37 AM, josef radinger cheese@nosuchhost.net wrote:
hi
i have a metro cluster (rather old) which is currently responding very slowly. 7-mode 8.1.4
there is only one aggregate per head, filled at around 72% one one head and 79% on the other head. attached is a statit and sysstat -x 1 from one head.
i see lots of partial stripes and only several full stripes. i assume this should mean not enough free space, which should imho not be a problem at my aggregates.
what is the correct procedure for performing a free space reallocation? i did: * stop all volume-reallocates * disable read_reallocation on all volumes * raid.lost_write.enable off * aggr options aggr0 resyncsnaptime 5 * reallocate start -A -o aggr0 * wait for finish of reallocate * aggr options aggr0 resyncsnaptime 60 * enable read_reallocation on all volumes * reenable all volume-level reallocates
my aggregates have options:
aggr options aggr0 root, diskroot, nosnap=off, raidtype=raid_dp, raidsize=20, ignore_inconsistent=off, snapmirrored=off, resyncsnaptime=60, fs_size_fixed=off, snapshot_autodelete=on, lost_write_protect=on, ha_policy=cfo, hybrid_enabled=off, percent_snapshot_space=5%, free_space_realloc=off
any advice? josef
_______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
performance advisor shows the following: read latency on a vmware-datastore at around 5-20ms. write latency at around 10-15ms with peaks: "other" latency at up to 500ms, i'm quite sure this other is my problem. but what me bothers is the stripe ratio: 2428.65 partial stripes 85.83 full stripes my knowledge is that i should have a lot more full stripes than partial ones. images are at http://www.nosuchhost.net/~cheese/temp/readandwrite.png http://www.nosuchhost.net/~cheese/temp/other.png my colleagues had troubles while patching several windows-systems residing in that datastore, as the systems got unresponsive and access got very slow. On Fri, 2016-03-25 at 18:42 +0000, Jeffrey Mohler wrote:
Are you write latency troubled, or read latency troubled?
I don't see free space frag as a huge issue, as lightly loaded as the spindles report to be.
_________________________________ Jeff Mohler Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 11:37 AM, josef radinger .net> wrote:
hi
i have a metro cluster (rather old) which is currently responding very slowly. 7-mode 8.1.4
there is only one aggregate per head, filled at around 72% one one head and 79% on the other head. attached is a statit and sysstat -x 1 from one head.
i see lots of partial stripes and only several full stripes. i assume this should mean not enough free space, which should imho not be a problem at my aggregates.
what is the correct procedure for performing a free space reallocation? i did:
- stop all volume-reallocates
- disable read_reallocation on all volumes
* raid.lost_write.enable off
- aggr options aggr0 resyncsnaptime 5
- reallocate start -A -o aggr0
- wait for finish of reallocate
- aggr options aggr0 resyncsnaptime 60
- enable read_reallocation on all volumes
- reenable all volume-level reallocates
my aggregates have options:
aggr options aggr0 root, diskroot, nosnap=off, raidtype=raid_dp, raidsize=20, ignore_inconsistent=off, snapmirrored=off, resyncsnaptime=60, fs_size_fixed=off, snapshot_autodelete=on, lost_write_protect=on, ha_policy=cfo, hybrid_enabled=off, percent_snapshot_space=5%, free_space_realloc=off
any advice? josef
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
They should be 100% on an empty aggregate..but still, spindles seem to handle the workload just fine.
What the history of CPU on the system..when did it work well last, what was CPU load then? _________________________________Jeff MohlerTech Yahoo, Storage Architect, Principal(831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 12:28 PM, josef radinger cheese@nosuchhost.net wrote:
performance advisor shows the following:read latency on a vmware-datastore at around 5-20ms.write latency at around 10-15ms with peaks:"other" latency at up to 500ms, i'm quite sure this other is my problem. but what me bothers is the stripe ratio: 2428.65 partial stripes 85.83 full stripesmy knowledge is that i should have a lot more full stripes than partial ones. images are athttp://www.nosuchhost.net/~cheese/temp/readandwrite.pnghttp://www.nosuchhost... my colleagues had troubles while patching several windows-systems residing in that datastore, as the systems got unresponsive and access got very slow.
On Fri, 2016-03-25 at 18:42 +0000, Jeffrey Mohler wrote: Are you write latency troubled, or read latency troubled?
I don't see free space frag as a huge issue, as lightly loaded as the spindles report to be.
_________________________________Jeff MohlerTech Yahoo, Storage Architect, Principal(831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 11:37 AM, josef radinger cheese@nosuchhost.net wrote:
hi
i have a metro cluster (rather old) which is currently responding very slowly. 7-mode 8.1.4
there is only one aggregate per head, filled at around 72% one one head and 79% on the other head. attached is a statit and sysstat -x 1 from one head.
i see lots of partial stripes and only several full stripes. i assume this should mean not enough free space, which should imho not be a problem at my aggregates.
what is the correct procedure for performing a free space reallocation? i did: * stop all volume-reallocates * disable read_reallocation on all volumes * raid.lost_write.enable off * aggr options aggr0 resyncsnaptime 5 * reallocate start -A -o aggr0 * wait for finish of reallocate * aggr options aggr0 resyncsnaptime 60 * enable read_reallocation on all volumes * reenable all volume-level reallocates
my aggregates have options:
aggr options aggr0 root, diskroot, nosnap=off, raidtype=raid_dp, raidsize=20, ignore_inconsistent=off, snapmirrored=off, resyncsnaptime=60, fs_size_fixed=off, snapshot_autodelete=on, lost_write_protect=on, ha_policy=cfo, hybrid_enabled=off, percent_snapshot_space=5%, free_space_realloc=off
any advice? josef
_______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
cpu on netapp is higher than it used to be. i think we see higher cpu than normal since around 1 month. we used to be at 30-40% and now we are slightly higher during work-hours at 50-60% with some peaks to around 90%. i'm currently not in my office and have no access to exact statistics.
On Fri, 2016-03-25 at 19:41 +0000, Jeffrey Mohler wrote:
They should be 100% on an empty aggregate..but still, spindles seem to handle the workload just fine.
What the history of CPU on the system..when did it work well last, what was CPU load then? _________________________________ Jeff Mohler Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 12:28 PM, josef radinger <cheese@nosuchhost .net> wrote:
performance advisor shows the following: read latency on a vmware-datastore at around 5-20ms. write latency at around 10-15ms with peaks: "other" latency at up to 500ms, i'm quite sure this other is my problem.
but what me bothers is the stripe ratio: 2428.65 partial stripes 85.83 full stripes my knowledge is that i should have a lot more full stripes than partial ones.
images are at http://www.nosuchhost.net/~cheese/temp/readandwrite.png http://www.nosuchhost.net/~cheese/temp/other.png
my colleagues had troubles while patching several windows-systems residing in that datastore, as the systems got unresponsive and access got very slow.
On Fri, 2016-03-25 at 18:42 +0000, Jeffrey Mohler wrote:
Are you write latency troubled, or read latency troubled?
I don't see free space frag as a huge issue, as lightly loaded as the spindles report to be.
_________________________________ Jeff Mohler Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 11:37 AM, josef radinger <cheese@nosuchho st.net> wrote:
hi
i have a metro cluster (rather old) which is currently responding very slowly. 7-mode 8.1.4
there is only one aggregate per head, filled at around 72% one one head and 79% on the other head. attached is a statit and sysstat -x 1 from one head.
i see lots of partial stripes and only several full stripes. i assume this should mean not enough free space, which should imho not be a problem at my aggregates.
what is the correct procedure for performing a free space reallocation? i did:
- stop all volume-reallocates
- disable read_reallocation on all volumes
* raid.lost_write.enable off
- aggr options aggr0 resyncsnaptime 5
- reallocate start -A -o aggr0
- wait for finish of reallocate
- aggr options aggr0 resyncsnaptime 60
- enable read_reallocation on all volumes
- reenable all volume-level reallocates
my aggregates have options:
aggr options aggr0 root, diskroot, nosnap=off, raidtype=raid_dp, raidsize=20, ignore_inconsistent=off, snapmirrored=off, resyncsnaptime=60, fs_size_fixed=off, snapshot_autodelete=on, lost_write_protect=on, ha_policy=cfo, hybrid_enabled=off, percent_snapshot_space=5%, free_space_realloc=off
any advice? josef
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
I believe you will find your correlations there.
_________________________________Jeff MohlerTech Yahoo, Storage Architect, Principal(831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 1:31 PM, josef radinger cheese@nosuchhost.net wrote:
cpu on netapp is higher than it used to be. i think we see higher cpu than normal since around 1 month. we used to be at 30-40% and now we are slightly higher during work-hours at 50-60% with some peaks to around 90%. i'm currently not in my office and have no access to exact statistics.
On Fri, 2016-03-25 at 19:41 +0000, Jeffrey Mohler wrote:
They should be 100% on an empty aggregate..but still, spindles seem to handle the workload just fine.
What the history of CPU on the system..when did it work well last, what was CPU load then? _________________________________ Jeff Mohler Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 12:28 PM, josef radinger <cheese@nosuchhost .net> wrote:
performance advisor shows the following: read latency on a vmware-datastore at around 5-20ms. write latency at around 10-15ms with peaks: "other" latency at up to 500ms, i'm quite sure this other is my problem.
but what me bothers is the stripe ratio: 2428.65 partial stripes 85.83 full stripes my knowledge is that i should have a lot more full stripes than partial ones.
images are at http://www.nosuchhost.net/~cheese/temp/readandwrite.png http://www.nosuchhost.net/~cheese/temp/other.png
my colleagues had troubles while patching several windows-systems residing in that datastore, as the systems got unresponsive and access got very slow.
On Fri, 2016-03-25 at 18:42 +0000, Jeffrey Mohler wrote:
Are you write latency troubled, or read latency troubled?
I don't see free space frag as a huge issue, as lightly loaded as the spindles report to be.
_________________________________ Jeff Mohler Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 11:37 AM, josef radinger <cheese@nosuchho st.net> wrote:
hi
i have a metro cluster (rather old) which is currently responding very slowly. 7-mode 8.1.4
there is only one aggregate per head, filled at around 72% one one head and 79% on the other head. attached is a statit and sysstat -x 1 from one head.
i see lots of partial stripes and only several full stripes. i assume this should mean not enough free space, which should imho not be a problem at my aggregates.
what is the correct procedure for performing a free space reallocation? i did:
- stop all volume-reallocates
- disable read_reallocation on all volumes
* raid.lost_write.enable off
- aggr options aggr0 resyncsnaptime 5
- reallocate start -A -o aggr0
- wait for finish of reallocate
- aggr options aggr0 resyncsnaptime 60
- enable read_reallocation on all volumes
- reenable all volume-level reallocates
my aggregates have options:
aggr options aggr0 root, diskroot, nosnap=off, raidtype=raid_dp, raidsize=20, ignore_inconsistent=off, snapmirrored=off, resyncsnaptime=60, fs_size_fixed=off, snapshot_autodelete=on, lost_write_protect=on, ha_policy=cfo, hybrid_enabled=off, percent_snapshot_space=5%, free_space_realloc=off
any advice? josef
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters

Josef,
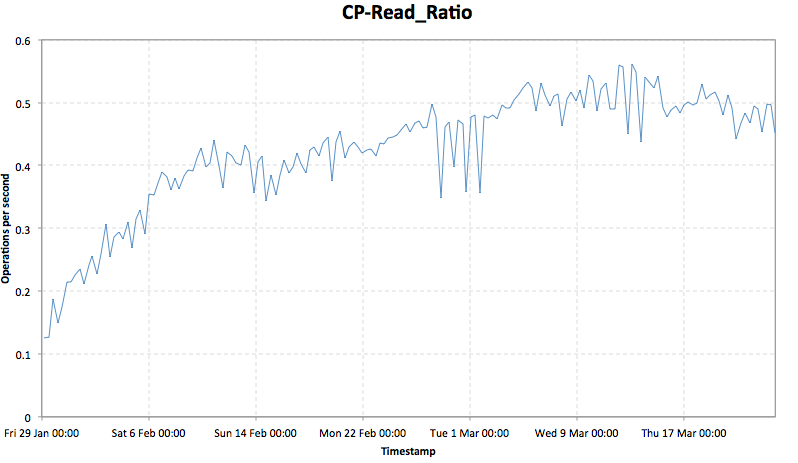
If you want to figure out if you are suffering from overhead from a lack of contagious freespace, you can compute it from statit with the following formula:
(CP Reads * chain) / (writes * chain) = CPRead Ratio. This can be done on any data disk in a raid group.
this will give you a value expressing the amount of correct parity(CP Read) workload vs write workload. below .5 is very efficientŠ .51 - .75 is usually not noticeable, but may need some attentionŠ .75 - 1 is bad, and more than 1 is _very_ badŠ Generally, the closer the ratio gets to 1:1 the less efficient the controller is, because it¹s having to do so much CP Read IO for a given write stripe.
The ratio has been steadily climbing since januaryŠ (see default.png attachment for chart). Is there a new type of workload on the system that is either quickly filling the aggr, or has a _lot_ of add and delete characteristics to it (creating lots of holes in the stripes), but even so, I¹d be surprised to see it affecting write latency on it¹s own this early in the game. it¹s usually got to be a bit higher before anyone notices, but there is no denying, there does seem to be some correlation with the latency increases on your VM Volumes as the ratio gets worseŠ
you will want your aggr option for free_space_realloc=on, I think, if you want to ensure that free space stays happy for the future. TR-3929 ŒReallocate Best Practices Guide¹ has all the gory details.
you may also want to take a peak at nfs-stat -d on your controllerŠ there are some indications of VMDK files that may not be aligned properly, and checking the last couple of months, there were a few spots where the controller ran out of partial write handling resourcesŠ probably not the overall issue, but Œone more thing¹ to be concerned with.
Paul Flores Professional Services Consultant 3 Americas Performance Assessments Team NetApp 281-857-6981 Direct Phone 713-446-5219 Mobile Phone paul.flores@netapp.com
http://www.netapp.com/us/solutions/professional/assessment.html
On 3/25/16, 3:29 PM, "toasters-bounces@teaparty.net on behalf of josef radinger" <toasters-bounces@teaparty.net on behalf of cheese@nosuchhost.net> wrote:
cpu on netapp is higher than it used to be. i think we see higher cpu than normal since around 1 month. we used to be at 30-40% and now we are slightly higher during work-hours at 50-60% with some peaks to around 90%. i'm currently not in my office and have no access to exact statistics.
On Fri, 2016-03-25 at 19:41 +0000, Jeffrey Mohler wrote:
They should be 100% on an empty aggregate..but still, spindles seem to handle the workload just fine.
What the history of CPU on the system..when did it work well last, what was CPU load then?
Jeff Mohler Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 12:28 PM, josef radinger <cheese@nosuchhost .net> wrote:
performance advisor shows the following: read latency on a vmware-datastore at around 5-20ms. write latency at around 10-15ms with peaks: "other" latency at up to 500ms, i'm quite sure this other is my problem.
but what me bothers is the stripe ratio: 2428.65 partial stripes 85.83 full stripes my knowledge is that i should have a lot more full stripes than partial ones.
images are at http://www.nosuchhost.net/~cheese/temp/readandwrite.png http://www.nosuchhost.net/~cheese/temp/other.png
my colleagues had troubles while patching several windows-systems residing in that datastore, as the systems got unresponsive and access got very slow.
On Fri, 2016-03-25 at 18:42 +0000, Jeffrey Mohler wrote:
Are you write latency troubled, or read latency troubled?
I don't see free space frag as a huge issue, as lightly loaded as the spindles report to be.
Jeff Mohler Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 11:37 AM, josef radinger <cheese@nosuchho st.net> wrote:
hi
i have a metro cluster (rather old) which is currently responding very slowly. 7-mode 8.1.4
there is only one aggregate per head, filled at around 72% one one head and 79% on the other head. attached is a statit and sysstat -x 1 from one head.
i see lots of partial stripes and only several full stripes. i assume this should mean not enough free space, which should imho not be a problem at my aggregates.
what is the correct procedure for performing a free space reallocation? i did:
- stop all volume-reallocates
- disable read_reallocation on all volumes
- raid.lost_write.enable off
- aggr options aggr0 resyncsnaptime 5
- reallocate start -A -o aggr0
- wait for finish of reallocate
- aggr options aggr0 resyncsnaptime 60
- enable read_reallocation on all volumes
- reenable all volume-level reallocates
my aggregates have options:
aggr options aggr0 root, diskroot, nosnap=off, raidtype=raid_dp, raidsize=20, ignore_inconsistent=off, snapmirrored=off, resyncsnaptime=60, fs_size_fixed=off, snapshot_autodelete=on, lost_write_protect=on, ha_policy=cfo, hybrid_enabled=off, percent_snapshot_space=5%, free_space_realloc=off
any advice? josef
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
{kind=link}
Ya...I wouldn't get near reallocation that you really =dont= need, given the CPU and disk use, and secondary effects that will add to your system.
Free space frag is only an issue, if it's an issue...and disk that 'not-busy' is soaking up the additional IO from it cleanly, and without any of the other secondary effects of fixing a problem that ain't there.
Work on the actual problem. Alignment...if it does exist as an issue, it chews up CPU, chews up disk IO, and makes the CP process slow and latent to client ACKs. _________________________________Jeff MohlerTech Yahoo, Storage Architect, Principal(831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 6:49 PM, "Flores, Paul" Paul.Flores@netapp.com wrote:
Josef,
If you want to figure out if you are suffering from overhead from a lack of contagious freespace, you can compute it from statit with the following formula:
(CP Reads * chain) / (writes * chain) = CPRead Ratio. This can be done on any data disk in a raid group.
this will give you a value expressing the amount of correct parity(CP Read) workload vs write workload. below .5 is very efficientŠ .51 - .75 is usually not noticeable, but may need some attentionŠ .75 - 1 is bad, and more than 1 is _very_ badŠ Generally, the closer the ratio gets to 1:1 the less efficient the controller is, because it¹s having to do so much CP Read IO for a given write stripe.
The ratio has been steadily climbing since januaryŠ (see default.png attachment for chart). Is there a new type of workload on the system that is either quickly filling the aggr, or has a _lot_ of add and delete characteristics to it (creating lots of holes in the stripes), but even so, I¹d be surprised to see it affecting write latency on it¹s own this early in the game. it¹s usually got to be a bit higher before anyone notices, but there is no denying, there does seem to be some correlation with the latency increases on your VM Volumes as the ratio gets worseŠ
you will want your aggr option for free_space_realloc=on, I think, if you want to ensure that free space stays happy for the future. TR-3929 ŒReallocate Best Practices Guide¹ has all the gory details.
you may also want to take a peak at nfs-stat -d on your controllerŠ there are some indications of VMDK files that may not be aligned properly, and checking the last couple of months, there were a few spots where the controller ran out of partial write handling resourcesŠ probably not the overall issue, but Œone more thing¹ to be concerned with.
Paul Flores Professional Services Consultant 3 Americas Performance Assessments Team NetApp 281-857-6981 Direct Phone 713-446-5219 Mobile Phone paul.flores@netapp.com
http://www.netapp.com/us/solutions/professional/assessment.html
On 3/25/16, 3:29 PM, "toasters-bounces@teaparty.net on behalf of josef radinger" <toasters-bounces@teaparty.net on behalf of cheese@nosuchhost.net> wrote:
cpu on netapp is higher than it used to be. i think we see higher cpu than normal since around 1 month. we used to be at 30-40% and now we are slightly higher during work-hours at 50-60% with some peaks to around 90%. i'm currently not in my office and have no access to exact statistics.
On Fri, 2016-03-25 at 19:41 +0000, Jeffrey Mohler wrote:
They should be 100% on an empty aggregate..but still, spindles seem to handle the workload just fine.
What the history of CPU on the system..when did it work well last, what was CPU load then? _________________________________ Jeff Mohler Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 12:28 PM, josef radinger <cheese@nosuchhost .net> wrote:
performance advisor shows the following: read latency on a vmware-datastore at around 5-20ms. write latency at around 10-15ms with peaks: "other" latency at up to 500ms, i'm quite sure this other is my problem.
but what me bothers is the stripe ratio: 2428.65 partial stripes 85.83 full stripes my knowledge is that i should have a lot more full stripes than partial ones.
images are at http://www.nosuchhost.net/~cheese/temp/readandwrite.png http://www.nosuchhost.net/~cheese/temp/other.png
my colleagues had troubles while patching several windows-systems residing in that datastore, as the systems got unresponsive and access got very slow.
On Fri, 2016-03-25 at 18:42 +0000, Jeffrey Mohler wrote:
Are you write latency troubled, or read latency troubled?
I don't see free space frag as a huge issue, as lightly loaded as the spindles report to be.
_________________________________ Jeff Mohler Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 11:37 AM, josef radinger <cheese@nosuchho st.net> wrote:
hi
i have a metro cluster (rather old) which is currently responding very slowly. 7-mode 8.1.4
there is only one aggregate per head, filled at around 72% one one head and 79% on the other head. attached is a statit and sysstat -x 1 from one head.
i see lots of partial stripes and only several full stripes. i assume this should mean not enough free space, which should imho not be a problem at my aggregates.
what is the correct procedure for performing a free space reallocation? i did:
- stop all volume-reallocates
- disable read_reallocation on all volumes
- raid.lost_write.enable off
- aggr options aggr0 resyncsnaptime 5
- reallocate start -A -o aggr0
- wait for finish of reallocate
- aggr options aggr0 resyncsnaptime 60
- enable read_reallocation on all volumes
- reenable all volume-level reallocates
my aggregates have options:
aggr options aggr0 root, diskroot, nosnap=off, raidtype=raid_dp, raidsize=20, ignore_inconsistent=off, snapmirrored=off, resyncsnaptime=60, fs_size_fixed=off, snapshot_autodelete=on, lost_write_protect=on, ha_policy=cfo, hybrid_enabled=off, percent_snapshot_space=5%, free_space_realloc=off
any advice? josef
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters

Lame question, but if the aggr is at standard 5% snapshot reserve, maybe freeing up that space may help (setting to 0).. Thanks
Steve Klise
From: <toasters-bounces@teaparty.netmailto:toasters-bounces@teaparty.net> on behalf of Jeffrey Mohler <jmohler@yahoo-inc.commailto:jmohler@yahoo-inc.com> Reply-To: Jeffrey Mohler <jmohler@yahoo-inc.commailto:jmohler@yahoo-inc.com> Date: Friday, March 25, 2016 at 7:23 PM To: "Flores, Paul" <Paul.Flores@netapp.commailto:Paul.Flores@netapp.com>, josef radinger <cheese@nosuchhost.netmailto:cheese@nosuchhost.net> Cc: "toasters@teaparty.netmailto:toasters@teaparty.net" <toasters@teaparty.netmailto:toasters@teaparty.net> Subject: Re: metro under high latency
Ya...I wouldn't get near reallocation that you really =dont= need, given the CPU and disk use, and secondary effects that will add to your system.
Free space frag is only an issue, if it's an issue...and disk that 'not-busy' is soaking up the additional IO from it cleanly, and without any of the other secondary effects of fixing a problem that ain't there.
Work on the actual problem. Alignment...if it does exist as an issue, it chews up CPU, chews up disk IO, and makes the CP process slow and latent to client ACKs.
_________________________________ Jeff Mohlermailto:jmohler@yahoo-inc.com Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 6:49 PM, "Flores, Paul" <Paul.Flores@netapp.commailto:Paul.Flores@netapp.com> wrote:
Josef,
If you want to figure out if you are suffering from overhead from a lack of contagious freespace, you can compute it from statit with the following formula:
(CP Reads * chain) / (writes * chain) = CPRead Ratio. This can be done on any data disk in a raid group.
this will give you a value expressing the amount of correct parity(CP Read) workload vs write workload. below .5 is very efficientŠ .51 - .75 is usually not noticeable, but may need some attentionŠ .75 - 1 is bad, and more than 1 is _very_ badŠ Generally, the closer the ratio gets to 1:1 the less efficient the controller is, because it¹s having to do so much CP Read IO for a given write stripe.
The ratio has been steadily climbing since januaryŠ (see default.png attachment for chart). Is there a new type of workload on the system that is either quickly filling the aggr, or has a _lot_ of add and delete characteristics to it (creating lots of holes in the stripes), but even so, I¹d be surprised to see it affecting write latency on it¹s own this early in the game. it¹s usually got to be a bit higher before anyone notices, but there is no denying, there does seem to be some correlation with the latency increases on your VM Volumes as the ratio gets worseŠ
you will want your aggr option for free_space_realloc=on, I think, if you want to ensure that free space stays happy for the future. TR-3929 ŒReallocate Best Practices Guide¹ has all the gory details.
you may also want to take a peak at nfs-stat -d on your controllerŠ there are some indications of VMDK files that may not be aligned properly, and checking the last couple of months, there were a few spots where the controller ran out of partial write handling resourcesŠ probably not the overall issue, but Œone more thing¹ to be concerned with.
Paul Flores Professional Services Consultant 3 Americas Performance Assessments Team NetApp 281-857-6981 Direct Phone 713-446-5219 Mobile Phone paul.flores@netapp.commailto:paul.flores@netapp.com
http://www.netapp.com/us/solutions/professional/assessment.html
On 3/25/16, 3:29 PM, "toasters-bounces@teaparty.netmailto:toasters-bounces@teaparty.net on behalf of josef radinger" <toasters-bounces@teaparty.netmailto:toasters-bounces@teaparty.net on behalf of cheese@nosuchhost.netmailto:cheese@nosuchhost.net> wrote:
cpu on netapp is higher than it used to be. i think we see higher cpu than normal since around 1 month. we used to be at 30-40% and now we are slightly higher during work-hours at 50-60% with some peaks to around 90%. i'm currently not in my office and have no access to exact statistics.
On Fri, 2016-03-25 at 19:41 +0000, Jeffrey Mohler wrote:
They should be 100% on an empty aggregate..but still, spindles seem to handle the workload just fine.
What the history of CPU on the system..when did it work well last, what was CPU load then?
Jeff Mohler Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 12:28 PM, josef radinger <cheese@nosuchhostmailto:cheese@nosuchhost .net> wrote:
performance advisor shows the following: read latency on a vmware-datastore at around 5-20ms. write latency at around 10-15ms with peaks: "other" latency at up to 500ms, i'm quite sure this other is my problem.
but what me bothers is the stripe ratio: 2428.65 partial stripes 85.83 full stripes my knowledge is that i should have a lot more full stripes than partial ones.
images are at http://www.nosuchhost.net/~cheese/temp/readandwrite.png http://www.nosuchhost.net/~cheese/temp/other.png
my colleagues had troubles while patching several windows-systems residing in that datastore, as the systems got unresponsive and access got very slow.
On Fri, 2016-03-25 at 18:42 +0000, Jeffrey Mohler wrote:
Are you write latency troubled, or read latency troubled?
I don't see free space frag as a huge issue, as lightly loaded as the spindles report to be.
Jeff Mohler Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 11:37 AM, josef radinger <cheese@nosuchhomailto:cheese@nosuchho st.net> wrote:
hi
i have a metro cluster (rather old) which is currently responding very slowly. 7-mode 8.1.4
there is only one aggregate per head, filled at around 72% one one head and 79% on the other head. attached is a statit and sysstat -x 1 from one head.
i see lots of partial stripes and only several full stripes. i assume this should mean not enough free space, which should imho not be a problem at my aggregates.
what is the correct procedure for performing a free space reallocation? i did:
- stop all volume-reallocates
- disable read_reallocation on all volumes
- raid.lost_write.enable off
- aggr options aggr0 resyncsnaptime 5
- reallocate start -A -o aggr0
- wait for finish of reallocate
- aggr options aggr0 resyncsnaptime 60
- enable read_reallocation on all volumes
- reenable all volume-level reallocates
my aggregates have options:
aggr options aggr0 root, diskroot, nosnap=off, raidtype=raid_dp, raidsize=20, ignore_inconsistent=off, snapmirrored=off, resyncsnaptime=60, fs_size_fixed=off, snapshot_autodelete=on, lost_write_protect=on, ha_policy=cfo, hybrid_enabled=off, percent_snapshot_space=5%, free_space_realloc=off
any advice? josef
Toasters mailing list Toasters@teaparty.netmailto:Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
Toasters mailing list Toasters@teaparty.netmailto:Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters

Eep no, that 5% aggr snapshot space is really important in metros.
On 26 March 2016 at 14:48, Klise, Steve Steve.Klise@wwt.com wrote:
Lame question, but if the aggr is at standard 5% snapshot reserve, maybe freeing up that space may help (setting to 0)..
Thanks
Steve Klise
From: toasters-bounces@teaparty.net on behalf of Jeffrey Mohler < jmohler@yahoo-inc.com> Reply-To: Jeffrey Mohler jmohler@yahoo-inc.com Date: Friday, March 25, 2016 at 7:23 PM To: "Flores, Paul" Paul.Flores@netapp.com, josef radinger < cheese@nosuchhost.net> Cc: "toasters@teaparty.net" toasters@teaparty.net Subject: Re: metro under high latency
Ya...I wouldn't get near reallocation that you really =dont= need, given the CPU and disk use, and secondary effects that will add to your system.
Free space frag is only an issue, if it's an issue...and disk that 'not-busy' is soaking up the additional IO from it cleanly, and without any of the other secondary effects of fixing a problem that ain't there.
Work on the actual problem. Alignment...if it does exist as an issue, it chews up CPU, chews up disk IO, and makes the CP process slow and latent to client ACKs.
Jeff Mohler jmohler@yahoo-inc.com Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 6:49 PM, "Flores, Paul" Paul.Flores@netapp.com wrote:
Josef,
If you want to figure out if you are suffering from overhead from a lack of contagious freespace, you can compute it from statit with the following formula:
(CP Reads * chain) / (writes * chain) = CPRead Ratio. This can be done on any data disk in a raid group.
this will give you a value expressing the amount of correct parity(CP Read) workload vs write workload. below .5 is very efficientŠ .51 - .75 is usually not noticeable, but may need some attentionŠ .75 - 1 is bad, and more than 1 is _very_ badŠ Generally, the closer the ratio gets to 1:1 the less efficient the controller is, because it¹s having to do so much CP Read IO for a given write stripe.
The ratio has been steadily climbing since januaryŠ (see default.png attachment for chart). Is there a new type of workload on the system that is either quickly filling the aggr, or has a _lot_ of add and delete characteristics to it (creating lots of holes in the stripes), but even so, I¹d be surprised to see it affecting write latency on it¹s own this early in the game. it¹s usually got to be a bit higher before anyone notices, but there is no denying, there does seem to be some correlation with the latency increases on your VM Volumes as the ratio gets worseŠ
you will want your aggr option for free_space_realloc=on, I think, if you want to ensure that free space stays happy for the future. TR-3929 ŒReallocate Best Practices Guide¹ has all the gory details.
you may also want to take a peak at nfs-stat -d on your controllerŠ there are some indications of VMDK files that may not be aligned properly, and checking the last couple of months, there were a few spots where the controller ran out of partial write handling resourcesŠ probably not the overall issue, but Œone more thing¹ to be concerned with.
Paul Flores Professional Services Consultant 3 Americas Performance Assessments Team NetApp 281-857-6981 Direct Phone 713-446-5219 Mobile Phone paul.flores@netapp.com
http://www.netapp.com/us/solutions/professional/assessment.html
On 3/25/16, 3:29 PM, "toasters-bounces@teaparty.net on behalf of josef radinger" <toasters-bounces@teaparty.net on behalf of cheese@nosuchhost.net> wrote:
cpu on netapp is higher than it used to be. i think we see higher cpu than normal since around 1 month. we used to be at 30-40% and now we are slightly higher during work-hours at 50-60% with some peaks to around 90%. i'm currently not in my office and have no access to exact statistics.
On Fri, 2016-03-25 at 19:41 +0000, Jeffrey Mohler wrote:
They should be 100% on an empty aggregate..but still, spindles seem to handle the workload just fine.
What the history of CPU on the system..when did it work well last, what was CPU load then?
Jeff Mohler Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 12:28 PM, josef radinger <cheese@nosuchhost .net> wrote:
performance advisor shows the following: read latency on a vmware-datastore at around 5-20ms. write latency at around 10-15ms with peaks: "other" latency at up to 500ms, i'm quite sure this other is my problem.
but what me bothers is the stripe ratio: 2428.65 partial stripes 85.83 full stripes my knowledge is that i should have a lot more full stripes than partial ones.
images are at http://www.nosuchhost.net/~cheese/temp/readandwrite.png http://www.nosuchhost.net/~cheese/temp/other.png
my colleagues had troubles while patching several windows-systems residing in that datastore, as the systems got unresponsive and access got very slow.
On Fri, 2016-03-25 at 18:42 +0000, Jeffrey Mohler wrote:
Are you write latency troubled, or read latency troubled?
I don't see free space frag as a huge issue, as lightly loaded as the spindles report to be.
Jeff Mohler Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
On Friday, March 25, 2016 11:37 AM, josef radinger <cheese@nosuchho st.net> wrote:
hi
i have a metro cluster (rather old) which is currently responding very slowly. 7-mode 8.1.4
there is only one aggregate per head, filled at around 72% one one head and 79% on the other head. attached is a statit and sysstat -x 1 from one head.
i see lots of partial stripes and only several full stripes. i assume this should mean not enough free space, which should imho not be a problem at my aggregates.
what is the correct procedure for performing a free space reallocation? i did:
- stop all volume-reallocates
- disable read_reallocation on all volumes
- raid.lost_write.enable off
- aggr options aggr0 resyncsnaptime 5
- reallocate start -A -o aggr0
- wait for finish of reallocate
- aggr options aggr0 resyncsnaptime 60
- enable read_reallocation on all volumes
- reenable all volume-level reallocates
my aggregates have options:
aggr options aggr0 root, diskroot, nosnap=off, raidtype=raid_dp, raidsize=20, ignore_inconsistent=off, snapmirrored=off, resyncsnaptime=60, fs_size_fixed=off, snapshot_autodelete=on, lost_write_protect=on, ha_policy=cfo, hybrid_enabled=off, percent_snapshot_space=5%, free_space_realloc=off
any advice? josef
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters

Jeffrey Mohler wrote:
Ya...I wouldn't get near reallocation that you really =dont= need, given the CPU and disk use, and secondary effects that will add to your system.
I agree. reallocate start -o -a <aggr_name> is *not* pleasant. Very impactful to the protocol latency in the system no matter how much iron you have in the heads and/or backend
However, if you don't have FSR on, and would really like to turn it on, you have no other choice really but to first run reallocate -A once...
Free space frag is only an issue, if it's an issue...and disk that 'not-busy' is soaking up the additional IO from it cleanly, and without any of the other secondary effects of fixing a problem that ain't there.
Well put. I agree.
/M
Work on the actual problem. Alignment...if it does exist as an issue, it chews up CPU, chews up disk IO, and makes the CP process slow and latent to client ACKs.
Jeff Mohler mailto:jmohler@yahoo-inc.com Tech Yahoo, Storage Architect, Principal (831)454-6712 YPAC Gold Member Twitter: @PrincipalYahoo CorpIM: Hipchat & Iris
Some comments from my IRL experiences with this. Caveat lector: YMMV. It all depends on the exact nature of the workload.
Paul Flores wrote:
If you want to figure out if you are suffering from overhead from a lack of contagious freespace, you can compute it from statit with the following formula:
(CP Reads * chain) / (writes * chain) = CPRead Ratio. This can be done on any data disk in a raid group.
My experience is that the chain lenghts don't really matter much to this procedure / calculation. It's the actual reads ops ws actula user_writes. The amount of data, the bandwidth, that flows there depends more than anything else on the nature of the workload.
And, short chain length = more cp_read ops... pretty much
this will give you a value expressing the amount of correct parity(CP Read) workload vs write workload. below .5 is very efficientŠ .51 - .75 is usually not noticeable, but may need some attentionŠ .75 - 1 is bad, and more than 1 is _very_ badŠ
Here's my ranges:
<1 is really good (certainly of you have many spinldes in your backend and the disk_busy is low overall)
1-1.5 is ok, may be noticed but not much (depends on the wokload)
2 and above is pretty bad. But may still not be a disaster. It depends ;-)
Note that it is pretty darn difficult for a system with a very random aggregated workload to keep this ratio <1 for any longer than max 5-7 days. It depends on the FAS model of course, but for FSR (free_space_reallocat option on the Aggrs) to keep this nice, it needs cycles and if the FG workload is heavy enough, it will invariably lag behind so slowly the ratio cp_reads/user_writes will grow larger and larger over time.
The *only* constructive thing one can do about this, is reallocate -A (aggregate reallocat). It's very impatctful w.r.t. protocol latency and my advice is: don't do it unless you have max 75% vol util of your Aggregate. With any less than that, it'll likely be a waste of pain to run a reallocate -A on that Aggr.
The ratio has been steadily climbing since januaryŠ (see default.png attachment for chart). Is there a new type of workload on the system that is either quickly filling the aggr, or has a _lot_ of add and delete characteristics to it (creating lots of holes in the stripes),
This is pretty much the worst thing you can do to WAFL and it is exactly the type of thing we have here too:
write, delete, write, delete, write, delete [lather, rinse, repeat]
Free Space Fragmentation will invariably result. And the only thing you can do is... [see above]
you will want your aggr option for free_space_realloc=on, I think, if you want to ensure that free space stays happy for the future. TR-3929 ŒReallocate Best Practices Guide¹ has all the gory details.
I agree. It is a *very* good idea to have FSR on. On all Aggrs. It *does* take some CPU cycles of course, and some IOPS too. Plus it may not be able to keep up, if there's too much of the type of workload pattern i described above. Sucks to be you and the only thing you can do about it is... [see above] :-) Or rather :-\
N.B. Make sure you turn on FSR *just* after you have finished a... yep, you guessed it, reallocate -A. Unless you did turn it on when the Aggregate was pristine. No..? I'm sorry.
BTW: before you run reallocate -A, turn off FSR on that Aggregate or you may be very surprised about the behaviour of the system or the end result (or both). And make sure no Dedup jobs run on anything on that Aggr during the reallocate -A, or it will almost certainly wreak havoc and ruin everything
If anyone wants to try this reallocate -A procedure out, you can shoot me an e-mail and I'll give you a procedure (1,2,3,... to follow). One which I've used many many times on very large Aggregates so it's well tested. It's semi manual so a bit of a pain, but better than nothing
Cheers, M
Michael, my testing shows that using just CPRead Ops / Write Ops generates a lot of false positives, as well as being less easy to predict when things go off. After sitting and thinking about _why_ for a good long while, I realized the underlying issue with just looking at ops, is that it doesn’t quantify the IO impact to disks for each op type in a comparable way. In other words, we are looking at a bucket of IO, and treating someone dumping 1 bucket into it the same as someone dumping 1 glass of water into it (for the purposes of figuring overhead).
So, if I want to quantify how much overhead is going towards dealing with a lack of contagious freespace in an aggregate (whose impact is how much time/IO I’m giving up from my write cycle to do reads to correct parity on the stripe), we need to calculate how much overhead IO is being consumed by the CPReads. if the IO overhead is low, it’s not going to affect performance, regardless of the count of ops for either type. So, lets say, for example, you have an aggregate with only 5 writes/s, with a chain length of 52… but the CP Reads are 20/s, with a chain length of 1 or 2.
If I just look at ops, I’m 20:5 CP Read:Writes, or _4_ on the ‘am I healthy’ number… if we take chain length into account, it’s 40:260 or .15 on the ‘am I healthy’ number. while it’s very true that high CP Read ops vs write ops is a good thing to check when a system is already suffering, it’s not always reliable metric to use if you are trying to monitoring a system in order to ensure this overhead doesn’t sneak up on you.
it’s possible to chart and trend both sets of numbers over months and make correlations with performance impacts with the ‘chain length’ method that are very predictable. There are way too many exceptions with the ‘ops’ method to reliably make correlations. just on a lark (and it’s actually in one of the factory CMPG configs now), I also added OPS to the existing CPREAD*CHAIN/WRITES*CHAIN math as a ‘multiplying’ factor, to extend the range of the numbers a bit more, and I found that until you are consistently over .75 on the chain maths, the ratio for CPREAD OPS/WriteOPs doesn’t go positive enough to move the ratio in a meaningful way. Once you go past that number, the addition of the positive number to the ratio that comes from having so much more extra CP magnifies the original ratio quite nicely, and highlights the point where things begin to feel bad on the controller, as opposed to just being very busy.
Since I’m all about automating and simplifying those kinds of things so an expert doesn’t have to identify all the exceptions, I prefer to push the ‘chain length’ method, because it doesn’t require much in the way of extra caveats.
pF
On 3/29/16, 9:12 AM, "toasters-bounces@teaparty.net on behalf of Michael Bergman" <toasters-bounces@teaparty.net on behalf of michael.bergman@ericsson.com> wrote:
Some comments from my IRL experiences with this. Caveat lector: YMMV. It all depends on the exact nature of the workload.
Paul Flores wrote:
If you want to figure out if you are suffering from overhead from a lack of contagious freespace, you can compute it from statit with the following formula:
(CP Reads * chain) / (writes * chain) = CPRead Ratio. This can be done on any data disk in a raid group.
My experience is that the chain lenghts don't really matter much to this procedure / calculation. It's the actual reads ops ws actula user_writes. The amount of data, the bandwidth, that flows there depends more than anything else on the nature of the workload.
And, short chain length = more cp_read ops... pretty much
this will give you a value expressing the amount of correct parity(CP Read) workload vs write workload. below .5 is very efficientŠ .51 - .75 is usually not noticeable, but may need some attentionŠ .75 - 1 is bad, and more than 1 is _very_ badŠ
Here's my ranges:
<1 is really good (certainly of you have many spinldes in your backend and the disk_busy is low overall)
1-1.5 is ok, may be noticed but not much (depends on the wokload)
2 and above is pretty bad. But may still not be a disaster. It depends ;-)
Note that it is pretty darn difficult for a system with a very random aggregated workload to keep this ratio <1 for any longer than max 5-7 days. It depends on the FAS model of course, but for FSR (free_space_reallocat option on the Aggrs) to keep this nice, it needs cycles and if the FG workload is heavy enough, it will invariably lag behind so slowly the ratio cp_reads/user_writes will grow larger and larger over time.
The *only* constructive thing one can do about this, is reallocate -A (aggregate reallocat). It's very impatctful w.r.t. protocol latency and my advice is: don't do it unless you have max 75% vol util of your Aggregate. With any less than that, it'll likely be a waste of pain to run a reallocate -A on that Aggr.
The ratio has been steadily climbing since januaryŠ (see default.png attachment for chart). Is there a new type of workload on the system that is either quickly filling the aggr, or has a _lot_ of add and delete characteristics to it (creating lots of holes in the stripes),
This is pretty much the worst thing you can do to WAFL and it is exactly the type of thing we have here too:
write, delete, write, delete, write, delete [lather, rinse, repeat]
Free Space Fragmentation will invariably result. And the only thing you can do is... [see above]
you will want your aggr option for free_space_realloc=on, I think, if you want to ensure that free space stays happy for the future. TR-3929 ŒReallocate Best Practices Guide¹ has all the gory details.
I agree. It is a *very* good idea to have FSR on. On all Aggrs. It *does* take some CPU cycles of course, and some IOPS too. Plus it may not be able to keep up, if there's too much of the type of workload pattern i described above. Sucks to be you and the only thing you can do about it is... [see above] :-) Or rather :-\
N.B. Make sure you turn on FSR *just* after you have finished a... yep, you guessed it, reallocate -A. Unless you did turn it on when the Aggregate was pristine. No..? I'm sorry.
BTW: before you run reallocate -A, turn off FSR on that Aggregate or you may be very surprised about the behaviour of the system or the end result (or both). And make sure no Dedup jobs run on anything on that Aggr during the reallocate -A, or it will almost certainly wreak havoc and ruin everything
If anyone wants to try this reallocate -A procedure out, you can shoot me an e-mail and I'll give you a procedure (1,2,3,... to follow). One which I've used many many times on very large Aggregates so it's well tested. It's semi manual so a bit of a pain, but better than nothing
Cheers, M -- Michael Bergman Sr Systems Analyst / Storage Architect michael.bergman@ericsson.com Engineering Hub Stockholm Phone +46 10 7152945 EMEA N, Operations North, IT Ops Kista SMS/MMS +46 70 5480835 Ericsson Torshamnsg 33, 16480 Sthlm, Sweden -- This communication is confidential. We only send and receive email on the basis of the terms set out at www.ericsson.com/email_disclaimer
Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
Paul Flores wrote:
you will want your aggr option for free_space_realloc=on, I think, if you want to ensure that free space stays happy for the future. TR-3929 'Reallocate Best Practices Guide' has all the gory details.
I have a copy of TR-3929. It's the latest to my knowledge, and from June 2012. Caveat lector! It does contain a no of details on how to run reallocate, and a bit about what it does. It's very sketchy though, and there's lots of things you really should now -- more recent knowledge from the field (among others created by yours truly over the past 24 months).
That said: yes, definitely you want free_space_realloc=no_redirect (very likely that's what you want in most scenarios, not "on" but need to understand the exact use case scenarios on the Filer in Q!) on all Aggregates and you want that set from start when they're pristine.
If not, then you *must* suffer a complete blkrealloc phase of a reallocate start -o -A <aggr_name> first and *immediately* when the blkrealloc phase has finished, set free_space_realloc={no_redirect|on}
/M
-
 Flores, Paul
Flores, Paul -
 Jeffrey Mohler
Jeffrey Mohler -
 josef radinger
josef radinger -
 Klise, Steve
Klise, Steve -
 Michael Bergman
Michael Bergman -
 Peta Thames
Peta Thames