
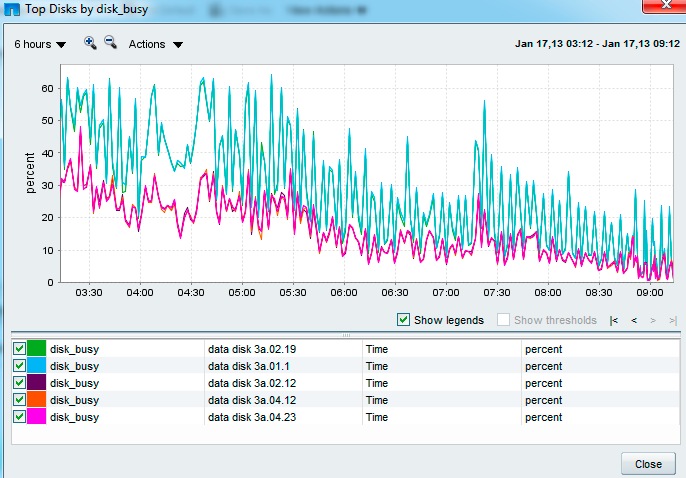
Running a perfstat now for netapp support and monitoring the disk busy % We seem to have one disk (3a.01) noticeably busier than the rest of the 95 disks in the aggregate Is this a potential hotspot? aggregate re-allocate indicated here?
thanks
On Jan 17, 2013, at 8:24 AM, Brian Beaulieu brian.beaulieu@gmail.com wrote:
What about other IO on the aggregate? Any other volume activity (snaps, resize)
I feel your pain. I've had one single VM cause IO spikes and thus latency. I had this happen when I moved the VM from an NFS datastore to a VMFS datastore to get more IO potential. Well, that extra IO was too much of a piece of the pie.
The other night I had all NFS/CIFS IO completely stop for a couple of minutes during a volume resize.
I love NFS+VMWare+NetApp but sometimes I hate it as well.
Brian _______________________________________________ Toasters mailing list Toasters@teaparty.net http://www.teaparty.net/mailman/listinfo/toasters
{kind=link}